








微软近日正式开源了其最新研发的文本转语音(tts)模型 vibevoice-1.5b,该模型以“超长时长、多说话人、高压缩比”为核心亮点,能够单次生成最长90分钟的连续语音流,并支持最多4位不同说话人同时发声,适用于复杂对话场景与长内容播报。

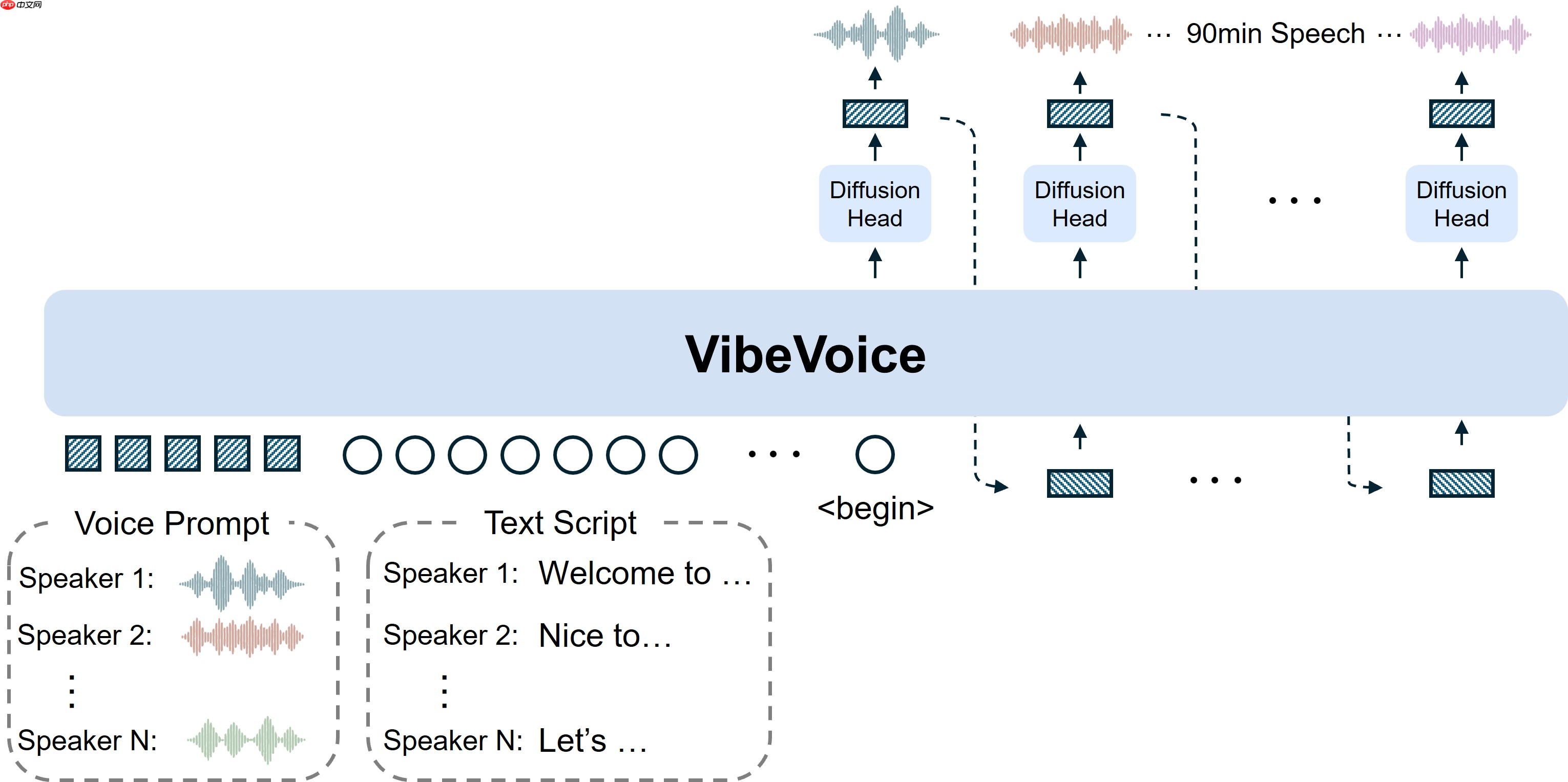
VibeVoice-1.5B 的关键技术突破在于其独特的双 Tokenizer 架构设计,模型由两个既独立又协同工作的模块组成。
1. 声学 Tokenizer:专注声音特征保留与高效压缩
该模块采用基于变分自编码器(VAE)的对称编码-解码结构,有效缓解了传统 VAE 在处理长语音序列时常见的“方差坍缩”问题,从而更好地保持语音多样性。
通过融合7阶段改进型 Transformer 与 1D 深度可分离因果卷积,声学 Tokenizer 可将 24kHz 高采样率的原始音频信号压缩为每秒仅 7.5 个潜在向量,实现高达 3200 倍的压缩比,相较主流 Encodec 模型效率提升达 80 倍。
2. 语义 Tokenizer:精准提取与文本对齐的语义信息
 微软文字转语音
微软文字转语音
微软文本转语音,支持选择多种语音风格,可调节语速。
 0 查看详情
0 查看详情
其架构沿用声学 Tokenizer 编码器结构,但去除了 VAE 中的随机采样机制,确保语义表示的确定性与稳定性。
在训练阶段,语义 Tokenizer 通过自动语音识别(ASR)任务进行监督学习,强化语音与文本之间的对齐能力;推理时则舍弃解码器部分,使整体推理速度提升约 40%。
这种双轨并行的设计策略,使得模型既能高度还原语音的自然音色、语调和节奏,又能确保输出内容与输入文本在语义层面高度一致,显著改善了传统 TTS 模型中常见的“情绪与音色错位”现象。
开源地址:
https://www.php.cn/link/4d0d3acf6bc4d8f28d53f73a2879dc3e
https://www.php.cn/link/5abad9111ffcd62ba77847ae11e1ae65
以上就是微软开源文本转语音模型 VibeVoice,支持最多 4 位说话人同时发声的详细内容,更多请关注创想鸟其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 chuangxiangniao@163.com 举报,一经查实,本站将立刻删除。
发布者:程序猿,转转请注明出处:https://www.chuangxiangniao.com/p/367916.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 