







华为诺亚方舟实验室推出高效选择性注意力算法esa,攻克大模型长文本处理难题!deepseek和月之暗面在长序列技术领域取得突破后,华为诺亚方舟实验室紧随其后,发布了全新高效选择性注意力算法(esa)。该算法通过巧妙的稀疏注意力机制设计,有效解决了大模型处理长文本时面临的计算瓶颈。

 论文地址:https://www.php.cn/link/860df126db301831a32055bea29fb4da
论文地址:https://www.php.cn/link/860df126db301831a32055bea29fb4da
ESA算法在显著提升计算效率的同时,保持了与全注意力方法相当甚至更高的准确率。它能够将大模型的上下文长度有效扩展至数倍,为长序列任务的应用开辟了新的可能性。
大语言模型的长序列推理一直是业界难题。模型训练需要巨大的算力和数据,而理想的方案是将短序列训练成果外推至长序列。然而,注意力计算复杂度随序列长度平方级增长,使得高效准确的长序列推理成为巨大挑战。
ESA算法正是针对这一挑战提出的创新解决方案。它通过对query和key进行低维压缩,大幅降低了token选择的计算复杂度。ESA算法灵活高效地选择关键token进行注意力计算,有效减轻了大模型处理长文本的计算负担。尤其是在高倍外推场景下,其性能甚至超越了全注意力算法。
ESA算法的核心:
高效选择: ESA采用基于query感知的token粒度选择机制,结合邻域影响力,避免了单纯选择top-ranked token导致的性能损失,精准定位关键信息。
注意力计算: ESA仅使用选择的关键token进行完整query和key的注意力计算,而非所有前序token,从而大幅降低计算复杂度。
ESA算法的创新之处在于其token粒度选择性注意力机制。不同于现有方法,ESA在预填充和解码阶段动态选择关键token,而非固定block选择或永久丢弃不重要token。它将query和key压缩至原维度的约3.2%,在低维空间计算重要性分数,显著降低计算复杂度。然后,选择topk token进行注意力计算,将复杂度从平方级降低至线性级。
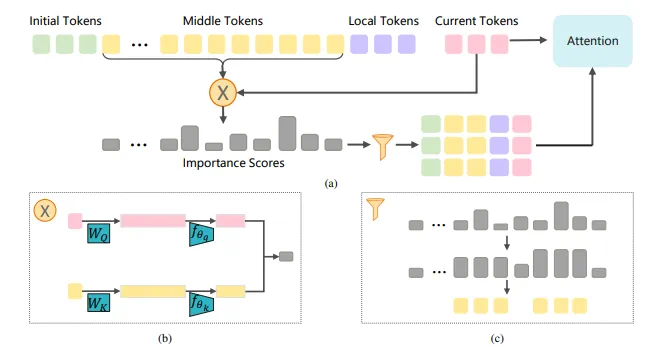
 ESA算法示意图
ESA算法示意图
ESA的具体实现细节包括:将输入序列token分为四部分,结合全局注意力和局部窗口注意力,并通过offline方式训练降维MLP,无需模型微调。 为了确保分数的相对大小,ESA对分数进行修正,并引入邻域影响力,进一步提升准确性。最终的注意力计算复杂度在长序列场景下可降低至原有的1.6%左右。


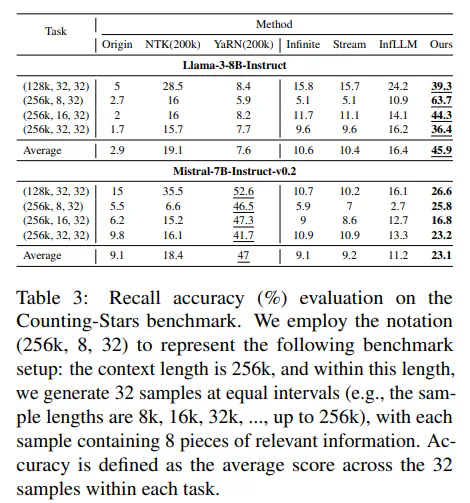

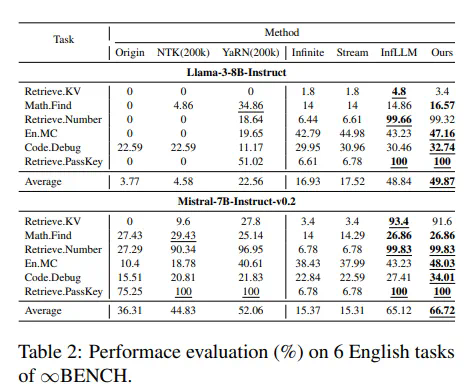

实验结果表明,ESA在多个公开的长序列基准测试中,性能优于full attention方法和其他同类型方法,尤其在多针检索任务中表现突出。
总结: ESA算法有效平衡了长序列外推场景下选择性注意力的灵活性和计算效率,在不增加模型参数的情况下扩展了上下文长度,为大模型的长序列应用带来了新的突破。 未来的研究方向将集中于探索更准确高效的token选择方法以及软硬件协同的高效外推方案。
以上就是稀疏注意力再添一员,华为诺亚推出高效选择注意力架构ESA的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/3049102.html

