







mme-cot:大型多模态模型链式思维推理能力评估基准
MME-CoT是由香港中文大学(深圳)、香港中文大学、字节跳动、南京大学、上海人工智能实验室、宾夕法尼亚大学和清华大学等机构联合研发的基准测试框架,用于评估大型多模态模型(LMMs)的链式思维(Chain-of-Thought, CoT)推理能力。该框架涵盖数学、科学、光学字符识别(OCR)、逻辑、时空和通用场景六大领域,包含1130个问题,每个问题都配有关键推理步骤标注和参考图像描述。MME-CoT采用三个新颖的评估指标:推理质量(逻辑合理性)、鲁棒性(对感知任务的干扰)和效率(推理步骤的相关性),对模型的推理能力进行全面评估。实验结果揭示了当前多模态模型在CoT推理中存在的关键问题,例如反思机制效率低下以及对感知任务的负面影响。
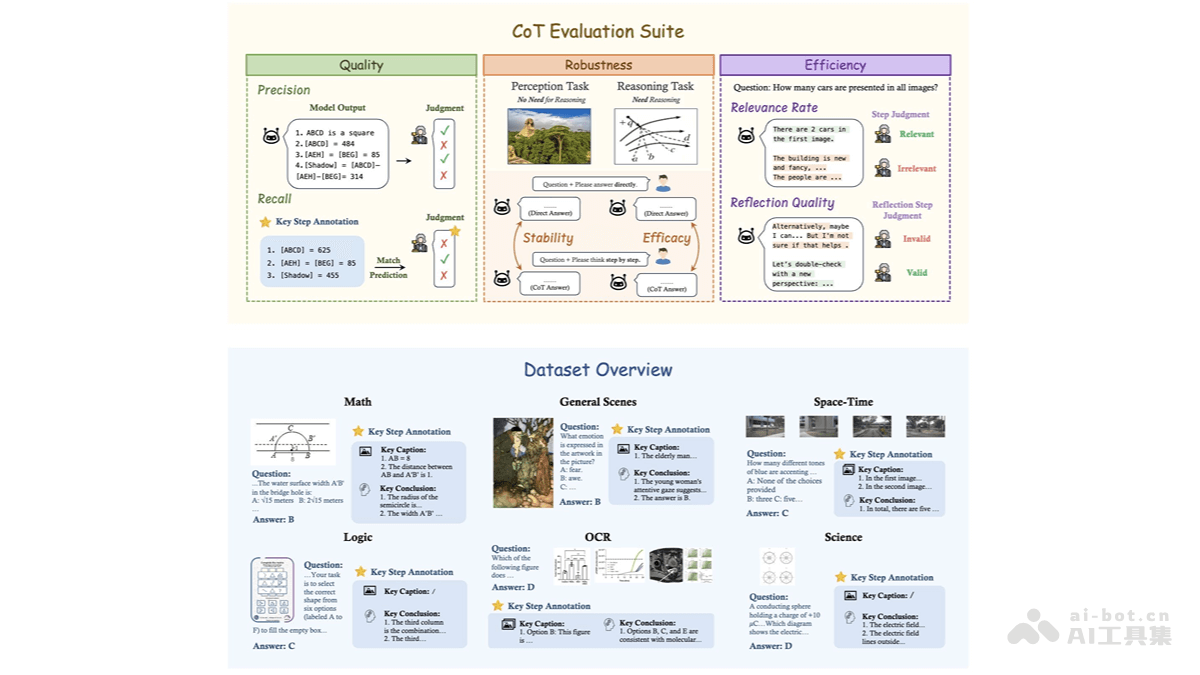

MME-CoT核心功能:
多领域评估: 覆盖六大领域,全面评估模型在不同场景下的推理能力。细粒度评估: 基于标注的推理步骤和图像描述,评估推理的逻辑合理性、鲁棒性和效率。问题诊断: 揭示多模态模型在CoT推理中的不足,例如反思机制的低效性及对感知任务的干扰。模型优化指导: 为多模态模型的设计和优化提供宝贵的参考,助力改进模型推理能力。
MME-CoT技术原理:
多模态数据集: 构建高质量的多模态数据集,包含1130个问题,涵盖六大领域和17个子类别,每个问题都标注了关键推理步骤和参考图像描述,用于评估模型的推理过程。细粒度评估指标:推理质量: 利用召回率和精确率评估推理步骤的逻辑合理性和准确性。推理鲁棒性: 通过稳定性和效能评估CoT对感知任务和推理任务的影响。推理效率: 使用相关性比例和反思质量评估推理步骤的相关性和反思的有效性。推理步骤分析: 利用GPT-4o等模型将模型输出解析为逻辑推理、图像描述和背景信息等步骤,并逐一评估。
MME-CoT资源链接:
项目官网: https://www.php.cn/link/b4c148b36ad0c21e46d1fc1f51d51585GitHub仓库: https://www.php.cn/link/b4c148b36ad0c21e46d1fc1f51d51585HuggingFace模型库: https://www.php.cn/link/b4c148b36ad0c21e46d1fc1f51d51585arXiv论文: https://www.php.cn/link/b4c148b36ad0c21e46d1fc1f51d51585
MME-CoT应用场景:
模型评估与比较: 作为标准化基准,用于评估和比较不同多模态模型在推理质量、鲁棒性和效率方面的表现。模型优化: 基于细粒度评估指标,识别模型推理过程中的问题,为模型优化提供方向。多模态研究: 为多模态推理研究提供工具,促进新型模型架构和训练方法的探索。教育与培训: 用于教育领域,帮助学生和研究人员理解多模态模型的推理逻辑。行业应用: 在智能教育、自动驾驶、医疗影像等领域评估和改进模型的实际应用表现。
以上就是MME-CoT— 港中文等机构推出评估视觉推理能力的基准框架的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/3048641.html

