







DataMan:提升大语言模型预训练效率的数据管理器
aixiv专栏持续报道全球顶尖ai研究成果。本文介绍由浙江大学和阿里巴巴千问团队合作完成的一项研究,该研究针对大语言模型(llms)预训练数据选择问题,提出了一种名为dataman的数据管理器,用于提升模型训练效率。


在模型规模不断增长的背景下,预训练数据质量至关重要。然而,现有方法往往依赖经验和直觉,缺乏系统性指导。DataMan通过逆向思维,即分析模型对不同数据质量的反应,来建立一套全面的数据质量评估标准。
一、基于逆向思维的质量标准构建
DataMan的研究人员采用四步法构建质量标准:
分析困惑度异常: 利用超级LLM分析预训练数据中困惑度(PPL)极高和极低的文本,找出影响模型性能的关键文本特征。迭代提炼标准: 基于步骤1的分析,迭代提炼出13个关键的文本质量标准,涵盖准确性、连贯性、语言风格、知识新颖性、主题聚焦等多个方面。构建综合评分体系: 除了13个标准外,还构建了一个综合“总体评分”,更全面地评估文本质量。验证标准有效性: 将超级LLM的评分与人工评分进行对比,验证标准的有效性,结果显示一致性超过95%。
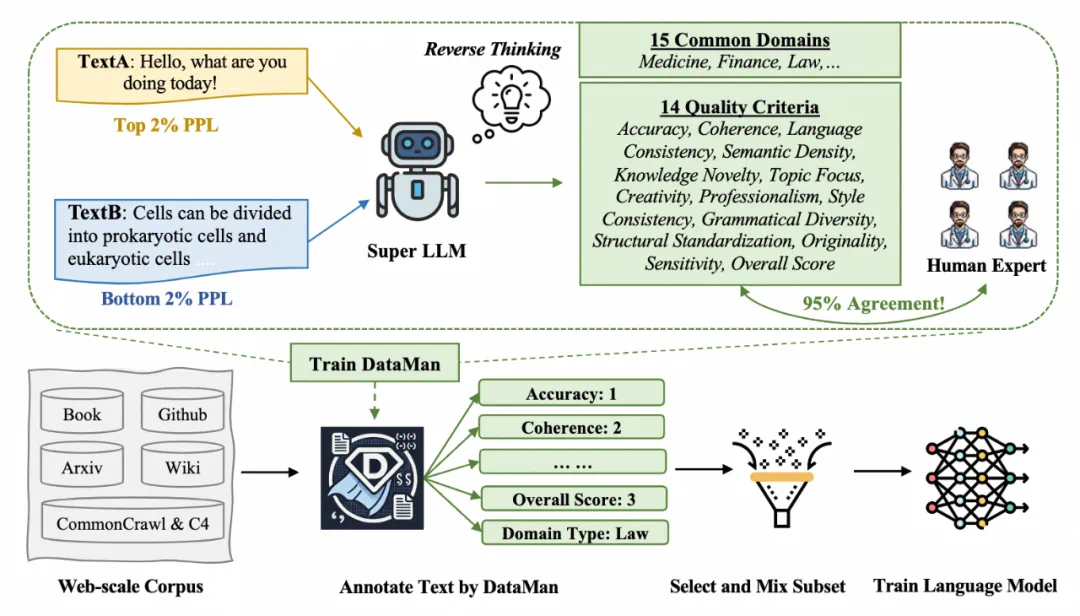

二、DataMan数据管理流程
DataMan是一个集数据标注、模型微调和数据采样于一体的数据管理器:
数据标注: 对SlimPajama语料库进行标注,为每个文档打上14个质量评分和15个应用领域的标签。模型微调: 使用Qwen2-1.5B作为基础模型,通过文本生成损失进行微调,使DataMan能够自动评分和识别领域。数据采样: 基于DataMan的评分和领域识别结果,采用top-k采样等策略,选择最优的数据子集进行模型训练。
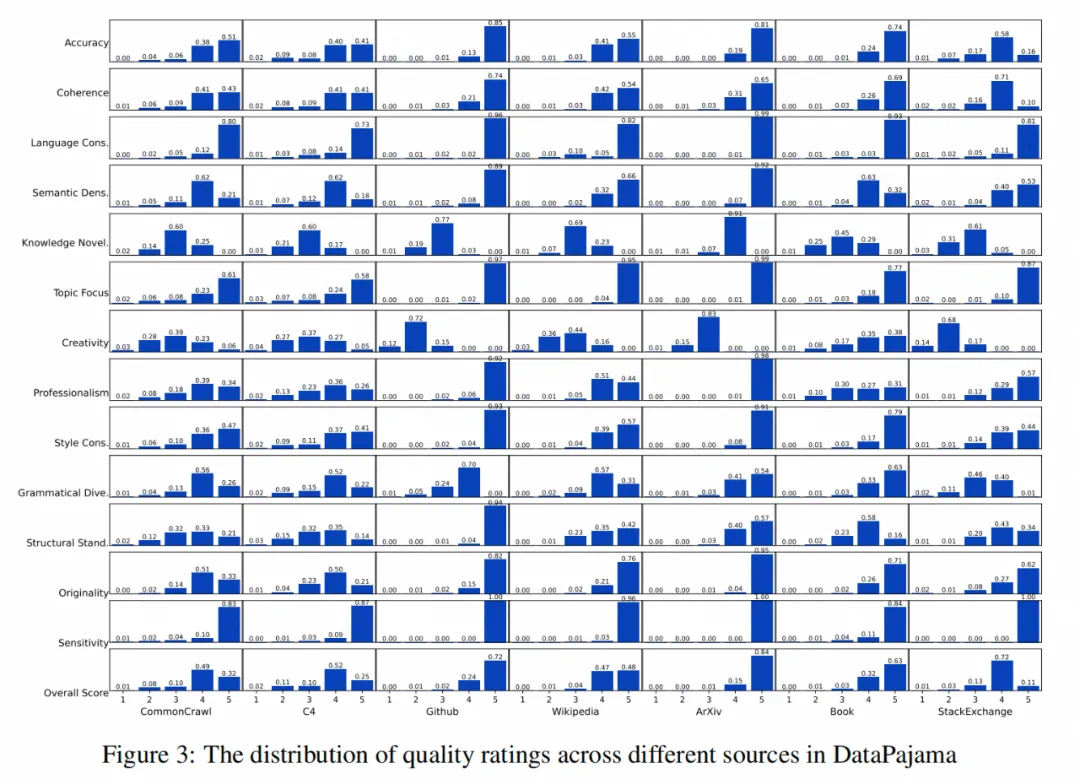

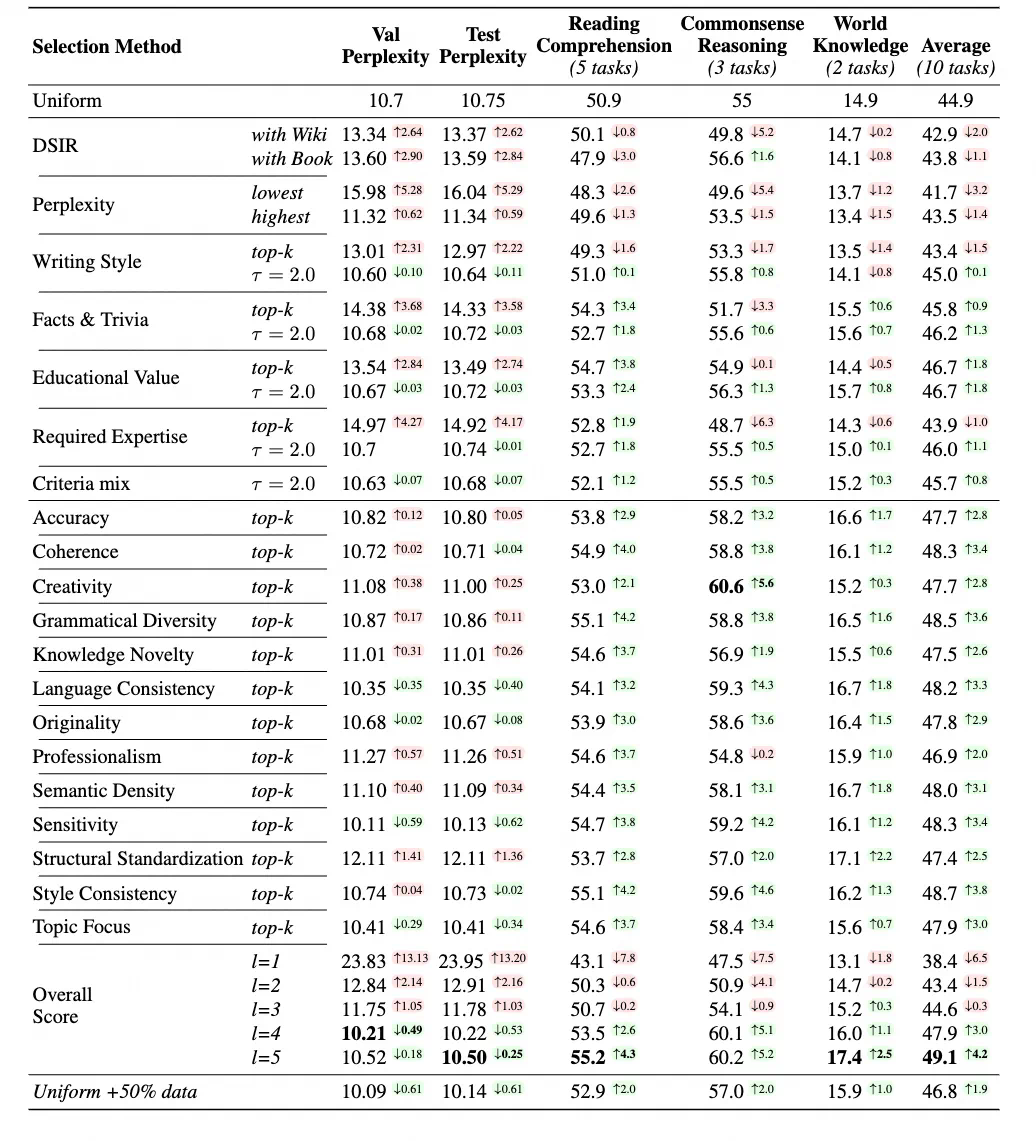
三、实验结果与分析
研究人员使用DataPajama (447B tokens)语料库进行实验,对比了DataMan与其他数据选择方法的性能:
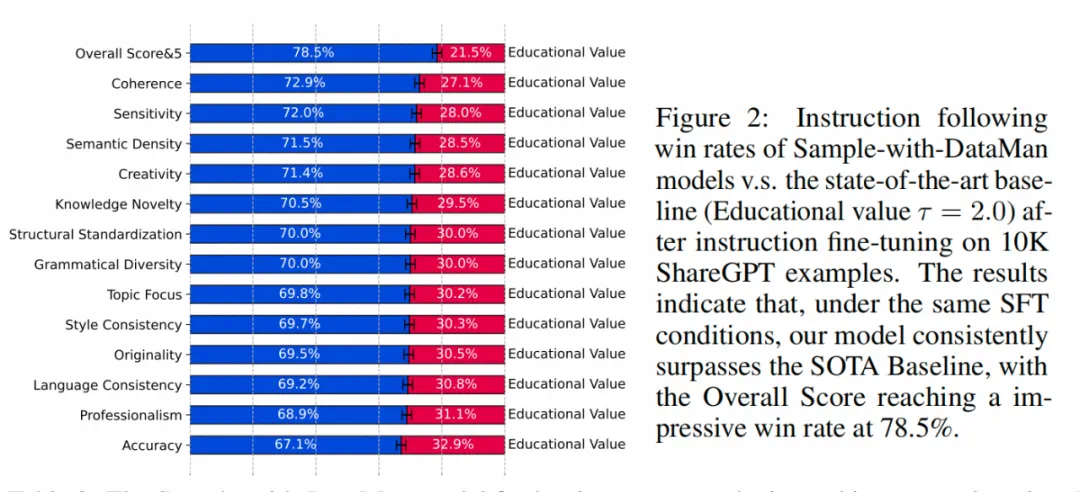
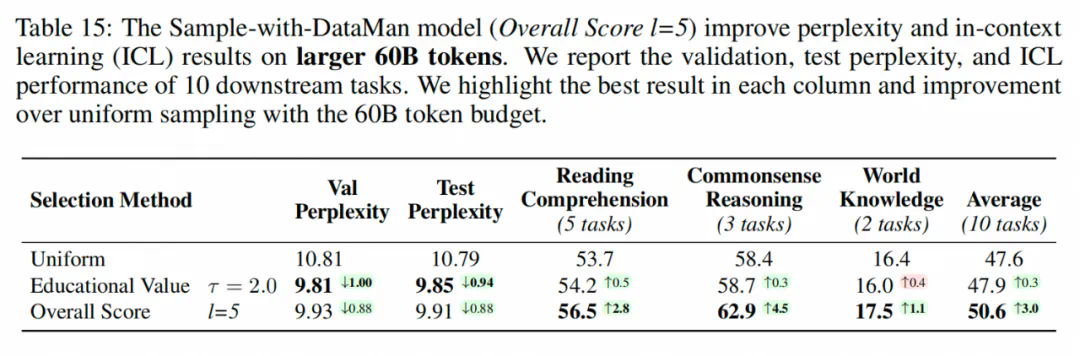
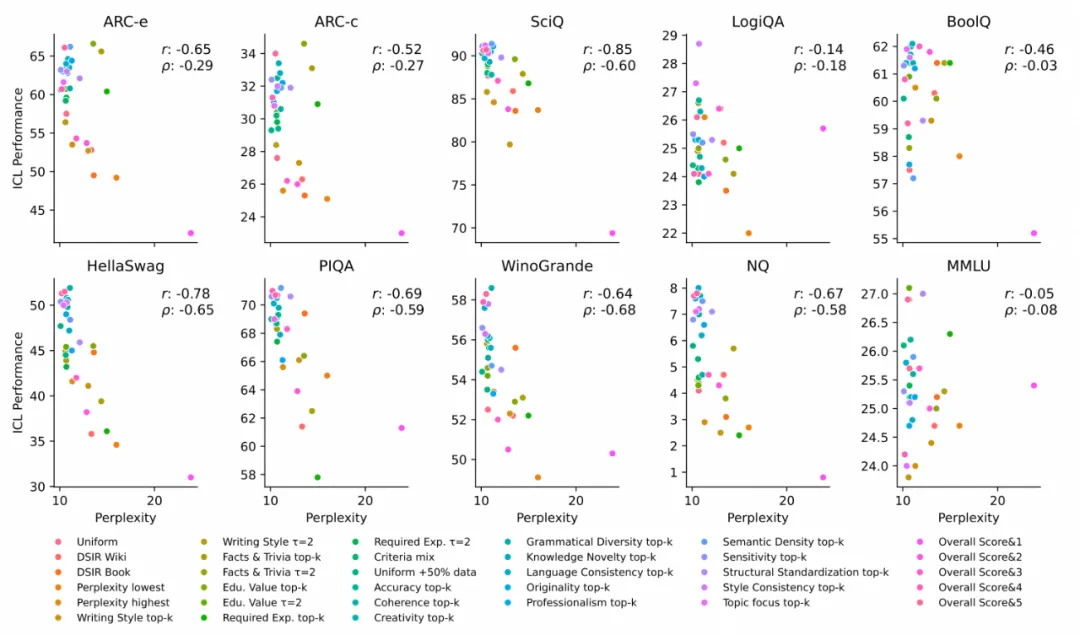
DataMan显著提升模型性能: 在语言建模、任务泛化和指令遵循等方面,使用DataMan选择的数据训练的模型均优于基线模型,指令遵循任务的胜率高达78.5%。有效进行领域数据混合: DataMan的领域识别能力可以有效地进行领域数据混合,进一步提升模型在特定领域的性能。数据量与性能正相关: 使用更大规模的数据集(60B tokens)进行训练,模型性能进一步提升。PPL与ICL性能的错位分析: 研究分析了困惑度(PPL)与上下文学习(ICL)性能之间的关系,发现域不匹配和ICL任务复杂性是造成错位的主要原因。






论文信息:
论文标题:DataMan: Data Manager for Pre-training Large Language Models作者单位:浙江大学 & 阿里巴巴论文链接:https://www.php.cn/link/5424eee00c1ab222f20cea406d120812 (链接可能需要更新为实际链接)
DataMan为大语言模型的预训练数据选择提供了一种新的思路和方法,其在提升模型性能和效率方面具有显著的潜力。
以上就是ICLR 2025|浙大、千问发布预训练数据管理器DataMan,53页细节满满的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/3048504.html

