







aixiv专栏持续报道全球顶尖ai研究成果,已收录2000余篇来自高校和企业实验室的学术技术文章,助力学术交流与传播。欢迎投稿或联系报道,邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com


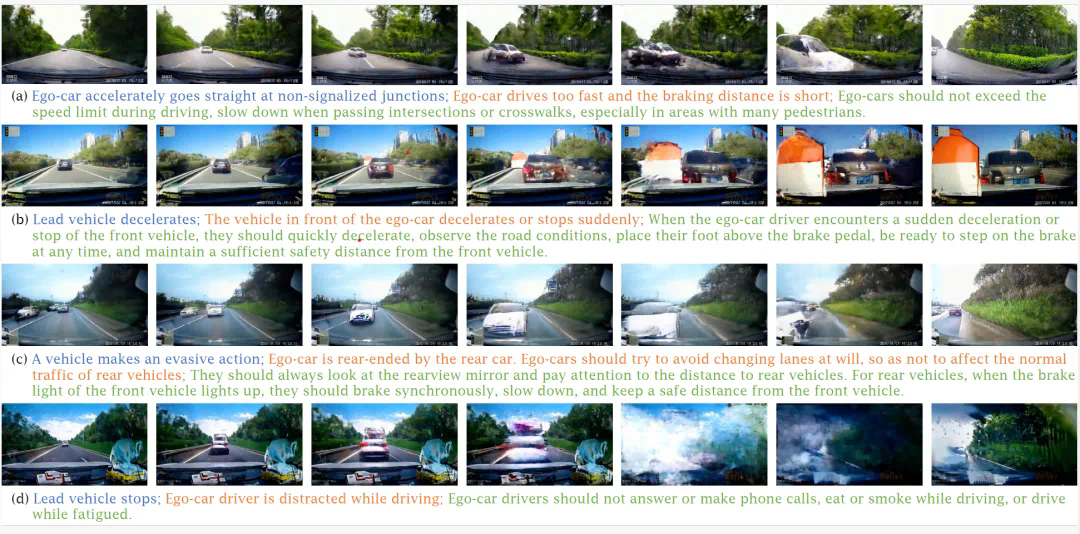
自动驾驶技术飞速发展,但复杂交通环境下的事故理解和预防仍是巨大挑战。例如,特斯拉FSD在中国市场的表现引发热议,其频繁违规行为凸显了现有方法的局限性。 事故数据稀缺也限制了自动驾驶系统应对突发事件的能力。
为此,光轮智能(Lightwheel)联合清华、香港科技大学等高校研究团队,研发了AVD2(Accident Video Diffusion for Accident Video Description)框架,提升自动驾驶事故场景的安全性能。
AVD2是一个创新的事故视频生成与描述框架,通过生成与自然语言描述高度一致的事故视频,增强对事故场景的建模能力。 团队同时贡献了EMM-AU(Enhanced Multi-Modal Accident Video Understanding)数据集,推动事故分析和预防研究。


项目主页:https://www.php.cn/link/42c88875bb90aeed57f01609fef5d9d7论文:https://www.php.cn/link/42c88875bb90aeed57f01609fef5d9d7EMM-AU数据集:https://www.php.cn/link/42c88875bb90aeed57f01609fef5d9d7代码:https://www.php.cn/link/42c88875bb90aeed57f01609fef5d9d7

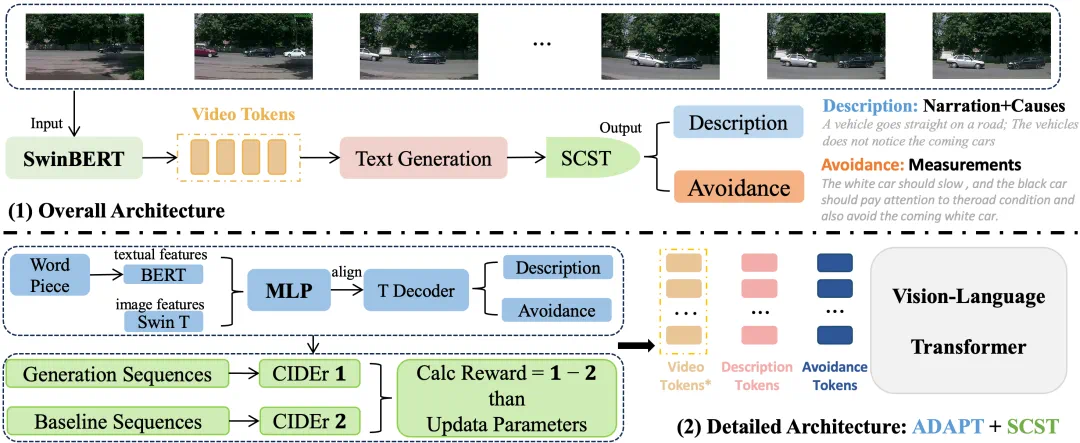
AVD2框架架构
AVD2框架由视频生成和事故分析两部分组成。视频生成部分利用Open-Sora 1.2模型,通过两阶段微调,基于MM-AU数据集预训练,再用2000个真实事故视频进行精调,生成高保真事故视频。 为了提升视频质量,采用RRDBNet模型进行超分辨率处理。
事故分析部分结合视频理解和自然语言处理技术,完成两个任务:
车辆行为描述和原因分析(及规避方法): 生成描述车辆行为的句子和原因解释,并提出规避事故的建议。多任务学习与文本生成: 使用Vision-Language Transformer进行多任务学习,联合训练行为描述和原因解释(预防措施)任务,提高整体性能。 SCST机制优化文本生成质量。

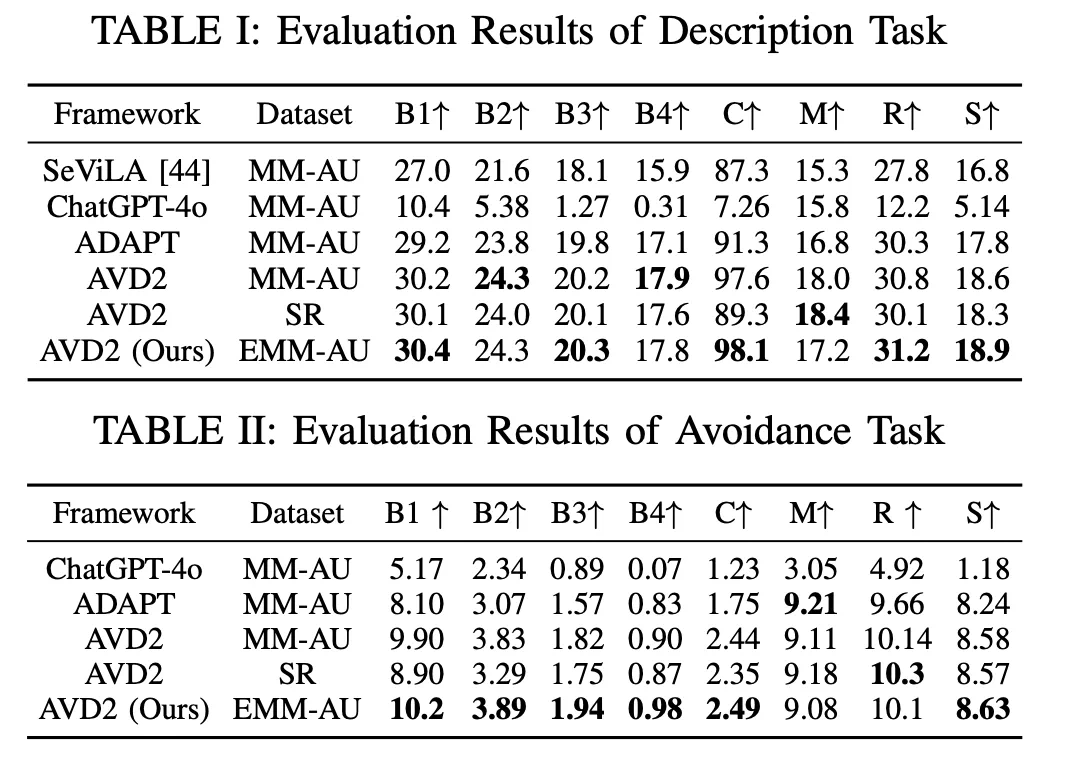
实验结果与可视化
AVD2在多个评测指标上优于ADAPT框架。下图展示了AVD2在不同数据集上的性能对比:

下图展示了AVD2对事故场景的可视化分析结果:




未来,研究团队将继续优化AVD2框架,并将其应用于光轮智能的自动驾驶系统中,推动自动驾驶技术的安全落地。
参考文献:
https://www.php.cn/link/42c88875bb90aeed57f01609fef5d9d7https://www.php.cn/link/42c88875bb90aeed57f01609fef5d9d7https://www.php.cn/link/42c88875bb90aeed57f01609fef5d9d7
以上就是ICRA 2025|清华x光轮:自驾世界模型生成和理解事故场景的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/3048166.html

