







华中科技大学、字节跳动和香港大学联合团队研发了一种名为liquid的极简统一多模态生成框架,该框架无需复杂的外部视觉模块,即可实现图像生成和理解。liquid巧妙地利用vqgan将图像编码为离散视觉token,并将其与文本token整合到同一词表空间,从而使现有的大型语言模型(llm)能够直接处理视觉信息,无需任何结构修改。


这项研究颠覆了传统多模态大模型(MLLM)依赖外部视觉模块(如CLIP或扩散模型)的范式,解决了系统臃肿和扩展受限的问题。研究团队首次证明了统一表征下的多模态能力遵循LLM的尺度定律,并且视觉生成和理解任务可以双向互促,为通用多模态智能的架构设计提供了新的方向。


论文标题:Liquid: Language Models are Scalable and Unified Multi-modal Generators论文链接:https://www.php.cn/link/99e71865a8531658d3eb31c17119b66e主页链接:https://www.php.cn/link/99e71865a8531658d3eb31c17119b66e
Liquid的核心优势:
Liquid在训练成本方面显著优于现有方法,例如,相比于从头训练的Chameleon,Liquid节省了100倍的训练成本,同时实现了更强的多模态能力。其关键创新在于:
极简架构: 摒弃了复杂的外部视觉模块,直接将图像信息融入LLM的词表空间。规模化优势: 研究发现,随着LLM规模的扩大,多模态训练对语言能力的负面影响逐渐减弱,甚至可以实现“零冲突共生”。双向互促: 视觉理解和生成任务通过共享表征空间,实现双向促进,提升整体性能。
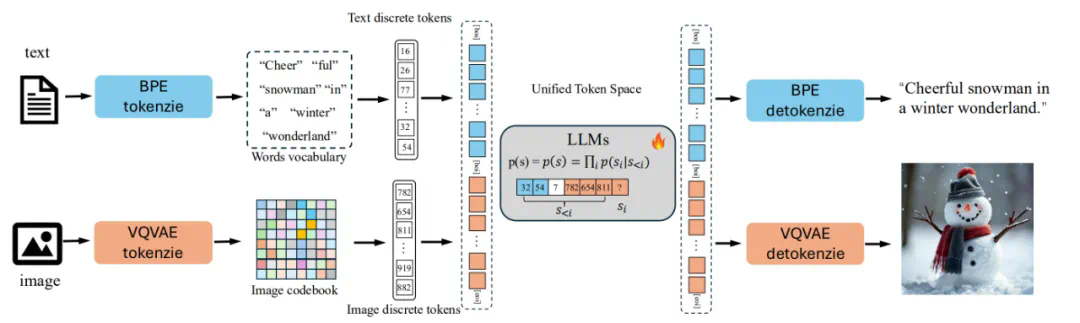

Liquid采用VQGAN作为图像分词器,将图像转换为离散的视觉token,并将其与文本token混合输入LLM进行训练。该框架保留了LLM原有的“下一token预测”训练目标,无需修改LLM的结构。
研究团队通过对不同规模LLM的实验,验证了Liquid的尺度规律统一性、规模化解耦效应和跨任务互惠性,并取得了显著的性能提升,在图像生成和视觉理解任务上都达到了领先水平。
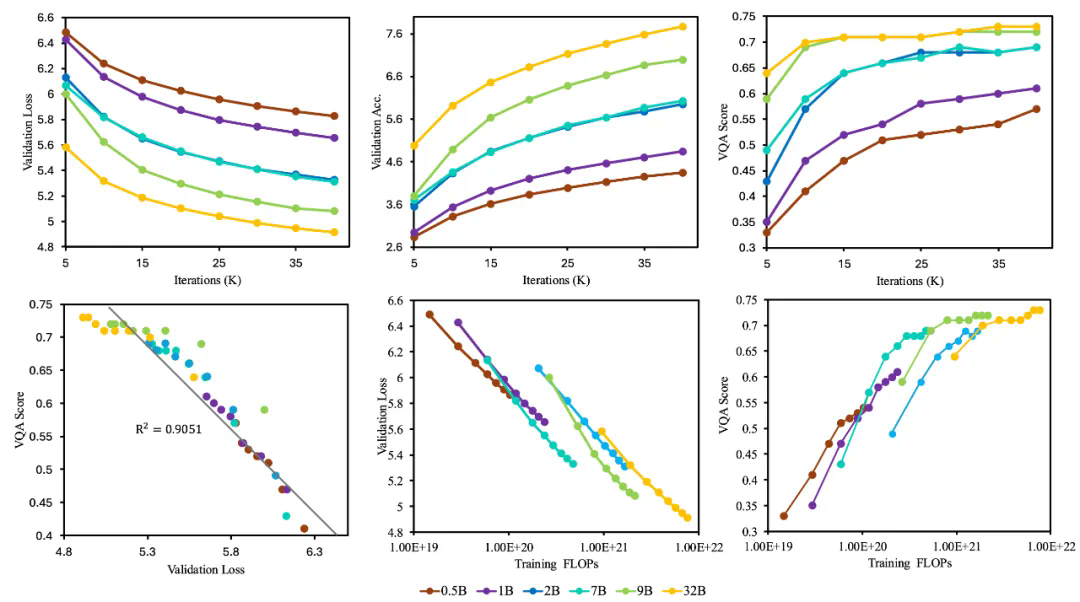





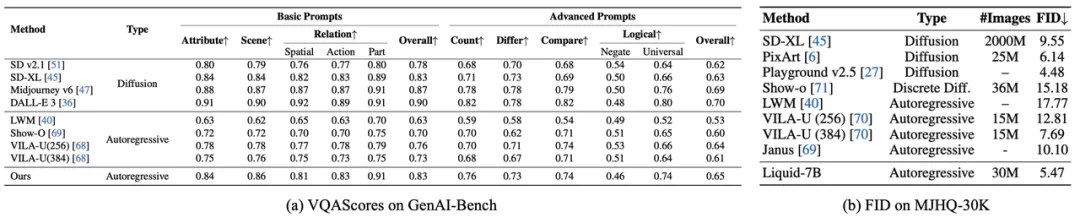

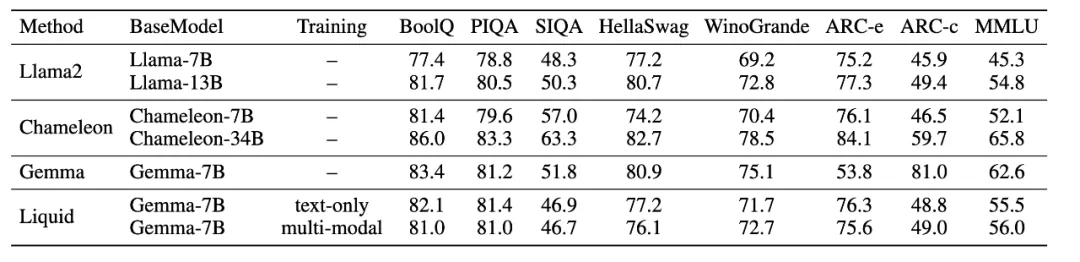

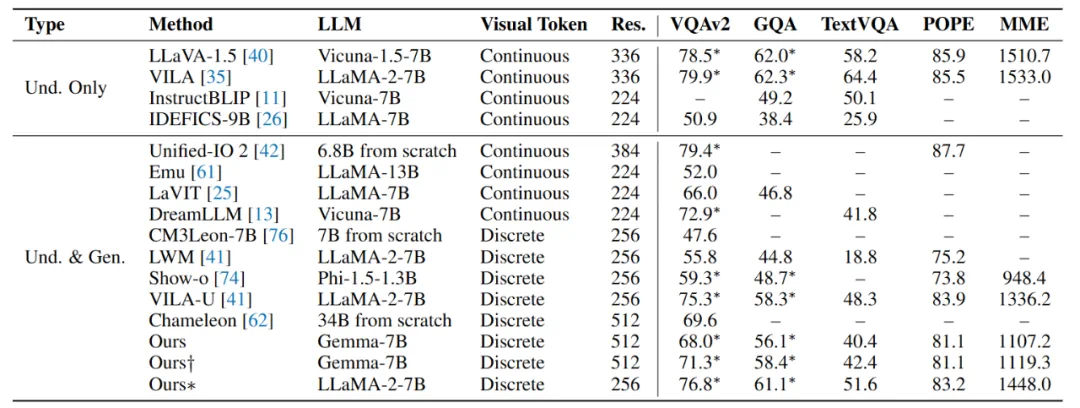

Liquid的出现为多模态大模型的发展提供了新的思路,其极简的架构和优异的性能,预示着未来多模态人工智能技术将朝着更轻量化、更高效的方向发展。
以上就是生成与理解相互促进!华科字节提出Liquid,揭示统一多模态模型尺度规律!的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/3048114.html

