







aixiv专栏:探索mom:混合记忆模型,兼顾强大的记忆扩展能力和低序列复杂度
AIxiv专栏持续关注并报道全球顶尖AI学术研究和技术进展,至今已发布超过2000篇高质量文章。欢迎投稿或联系报道:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
回顾AGI发展历程,从最初的预训练模型和数据规模扩展,到后续的精调和强化学习反馈规模扩展,再到推理能力的强化学习扩展,始终围绕着寻找正确的扩展维度展开。Transformer架构自2017年问世以来经久不衰,其强大的“无损记忆”能力功不可没,但也需要付出巨大的键值对缓存代价。换言之,Transformer架构拥有强大的记忆扩展能力。
DeepSeek NSA通过三种方式压缩键值对实现稀疏注意力,但这并非优雅的解决方案,因为它以牺牲Transformer的记忆能力为代价换取效率提升。
另一方面,自2023年以来备受关注的线性序列建模方法(包括线性注意力机制、Mamba系列和RWKV系列)则走向另一个极端:仅维护固定大小的RNN记忆状态,通过门控机制和更新规则进行调整,但这种方法的性能上限较低,因此衍生出各种混合架构的折中方案,这些方案同样不够优雅。
我们认为,未来的模型架构应具备两大特性:强大的记忆扩展能力 + 关于序列长度的低复杂度。后者可通过高效的注意力机制实现,例如线性或稀疏注意力,是实现长序列建模的必要条件。而前者仍有待深入探索,我们将其称为“稀疏记忆”。
基于此,我们设计了MoM:混合记忆模型,它突破了现有主流线性序列建模方法中修改门控机制和RNN更新规则的模式,能够稀疏且无限制地扩展记忆大小。MoM通过路由器分发token(灵感源于MoE),维护多个键值对记忆,实现记忆维度的扩展。每个记忆单元又可以进行RNN风格的计算,因此整体训练复杂度与序列长度线性相关,推理复杂度则为常数级。此外,我们还设计了共享记忆和局部记忆协同工作,分别处理全局和局部信息。实验结果令人惊艳,尤其是在线性方法效果欠佳的召回密集型任务上表现突出,1.3B参数规模的MoM模型甚至已与Transformer架构不相上下。


论文地址:https://www.php.cn/link/6f0cdeedf664c24860cba8842e94b300代码地址:https://www.php.cn/link/6f0cdeedf664c24860cba8842e94b300未来集成于:https://www.php.cn/link/6f0cdeedf664c24860cba8842e94b300模型权重:https://www.php.cn/link/6f0cdeedf664c24860cba8842e94b300
方法细节
线性循环记忆
熟悉线性序列建模的读者可跳过此部分。
输入 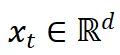
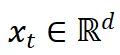 经过查询键值投影得到
经过查询键值投影得到 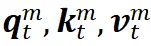
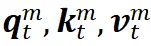 :
: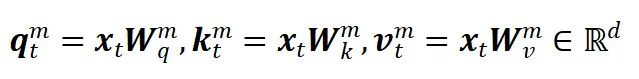
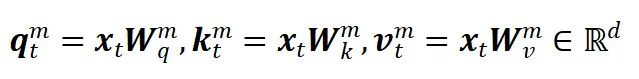
最简洁的循环形式线性序列建模方法(与最基本的线性注意力机制对应)按照以下公式进行RNN更新: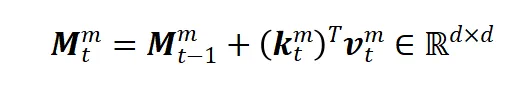
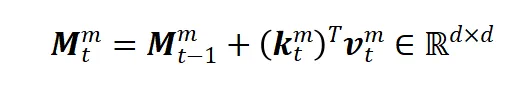
各种门控机制(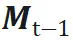
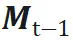 前面的)和更新规则(右边的)是对上述公式的改进,具体形式如下表所示:(各种方法本身符号不同,如Mamba、HGRN,此处为统一对比,全部对标到线性注意力形式。Titans方法将记忆更新规则视为优化器更新,其核心仍是SGD形式,暂忽略动量/权重衰减,用一个公式表达的话,写成这种梯度更新的形式是合理的。)
前面的)和更新规则(右边的)是对上述公式的改进,具体形式如下表所示:(各种方法本身符号不同,如Mamba、HGRN,此处为统一对比,全部对标到线性注意力形式。Titans方法将记忆更新规则视为优化器更新,其核心仍是SGD形式,暂忽略动量/权重衰减,用一个公式表达的话,写成这种梯度更新的形式是合理的。)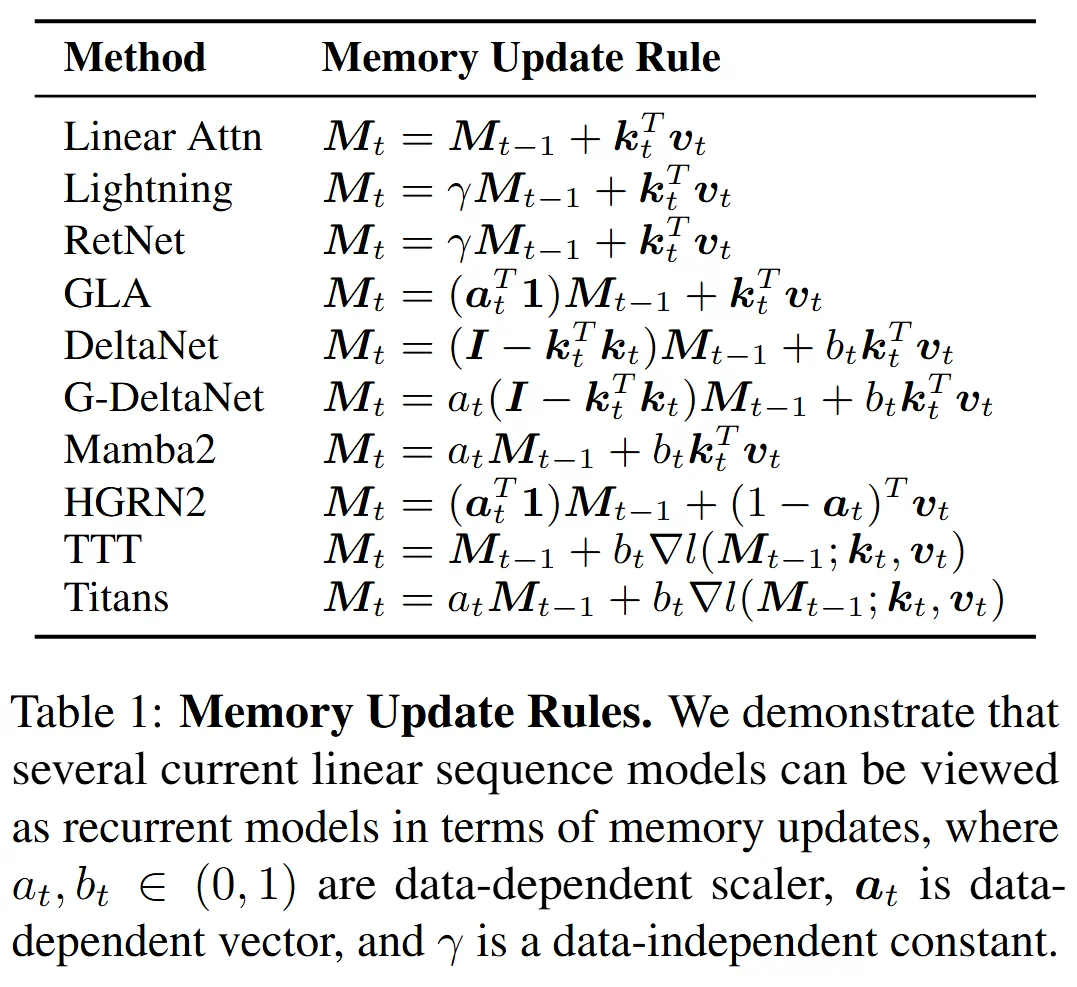

这些方法可进一步细分为不同类别(许多地方粗略地统称为线性RNN或RNN),论文暂未提及:
线性注意力、闪电注意力、RetNet、GLA、DeltaNet、门控DeltaNet属于线性注意力类;Mamba2属于SSM类,HGRN2属于线性RNN类;TTT、Titans属于测试时训练类。
混合记忆
MoM的思路非常简单,与MoE类似,根据token进行分发,通过路由器为每个token选择topk个记忆单元并计算各自权重: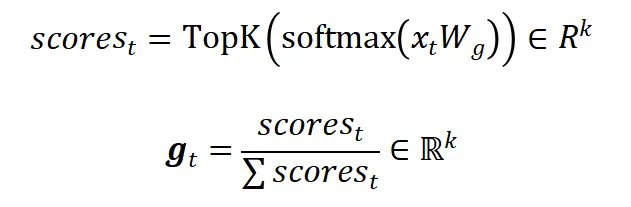
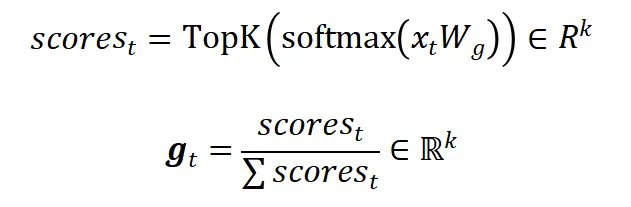
所有激活的topk个记忆单元按照各自权重加权求和得到混合记忆: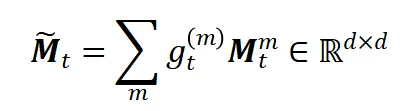
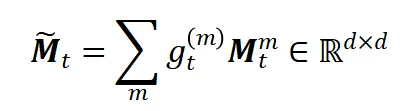
然后回到线性方法惯用的输出计算: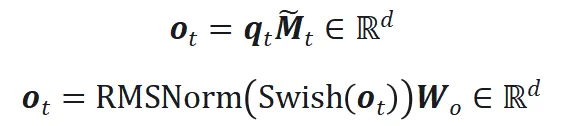
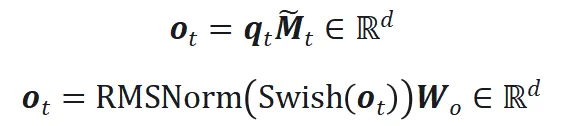
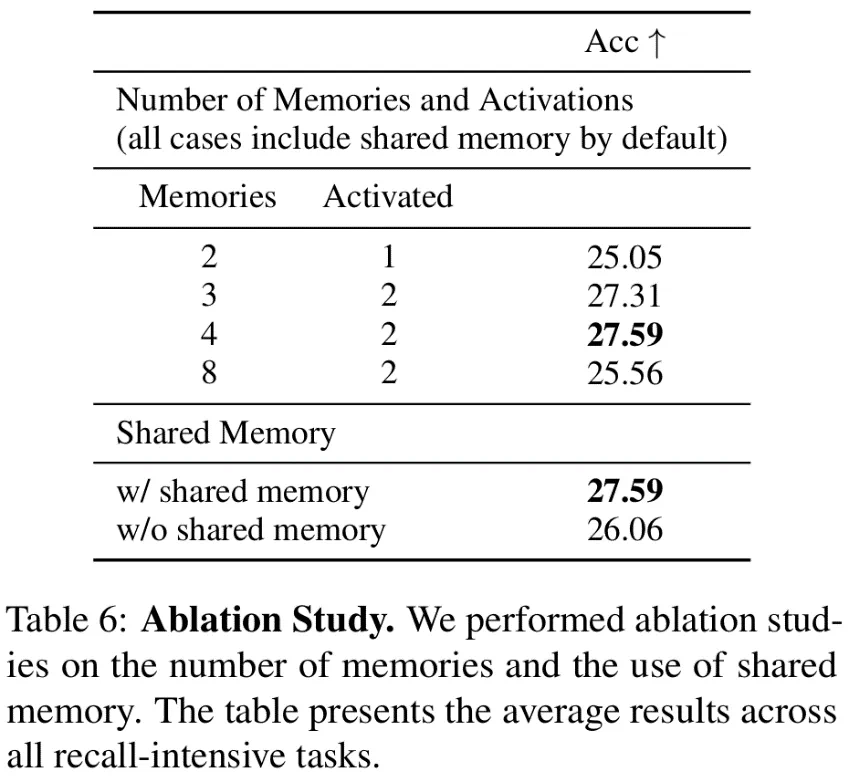
此外,我们引入了共享记忆的概念,即每个token都会经过这个始终激活的记忆单元,有助于模型获取全局信息。相对而言,其他稀疏激活的记忆单元更擅长获取局部信息。消融实验表明,共享记忆的存在对模型效果有积极作用。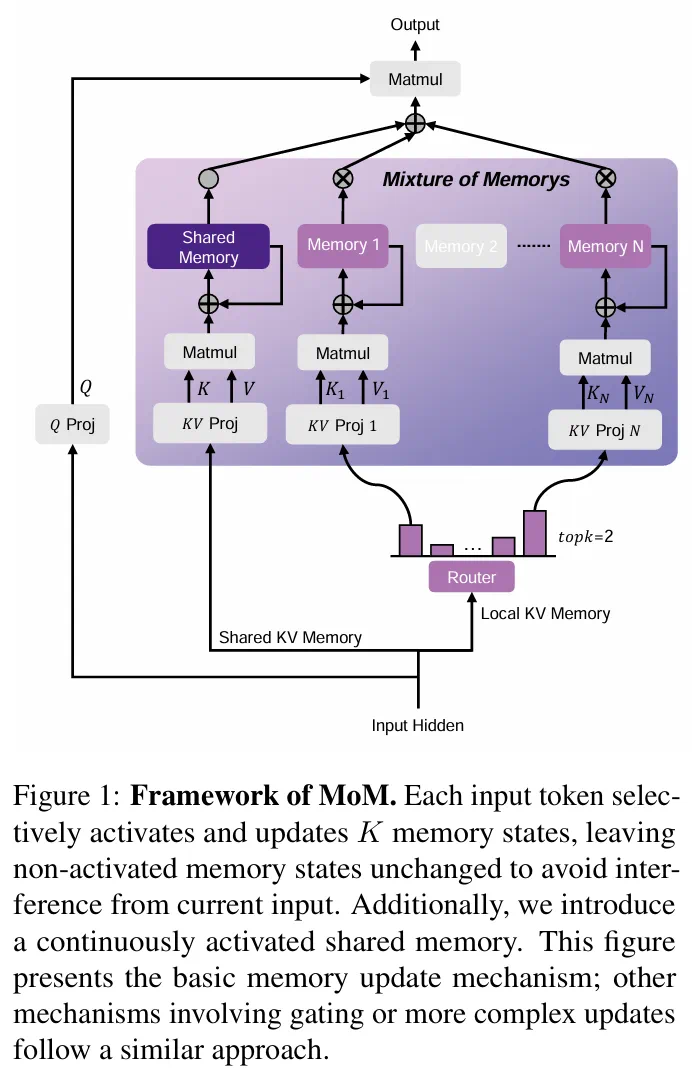

硬件高效实现
MoM的硬件高效Triton算子易于实现,其输出计算可简化为: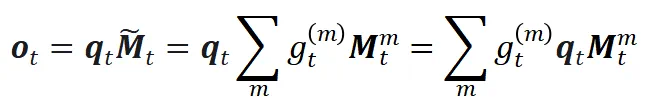
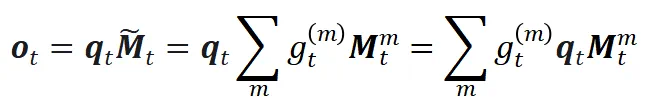
这意味着MoM中每个记忆单元的计算过程可以复用现有的单个算子,然后将所有记忆单元的输出加权求和。这与在算子内部先求和再计算输出在数学上是等价的。
实验结果
上下文召回密集型任务
线性序列建模方法由于记忆大小有限,在上下文召回密集型任务上的表现一直欠佳,而Transformer模型凭借其强大的无损记忆能力,擅长此类任务。因此,出现了各种层间混合模型来提升线性模型在此类任务上的效果。
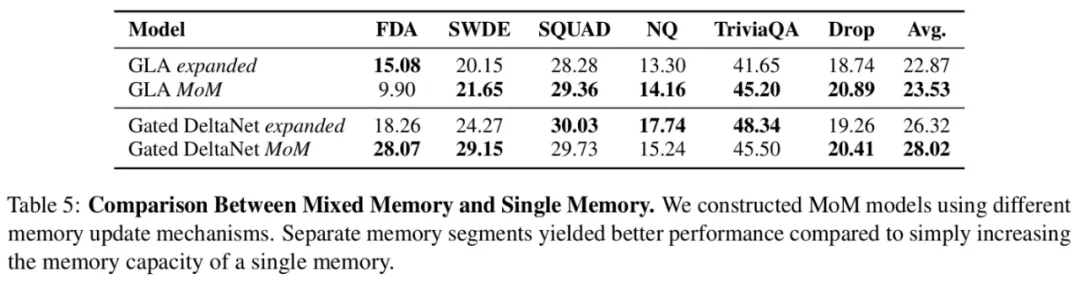
我们首先重点测试了这类任务(结果见下表),使用门控DeltaNet作为MoM的记忆计算形式(在记忆更新过程中,每个记忆单元都使用门控DeltaNet的门控机制和更新规则),总共4个局部稀疏记忆单元,激活2个,还有一个共享记忆单元。其中标†的模型来自开源项目(https://www.php.cn/link/6f0cdeedf664c24860cba8842e94b300),未标†的是我们从头预训练的模型。
结果显示MoM单纯地效果更好,这与预期一致,扩展记忆大小后,效果优于其他线性方法。令人意外的是,1.3B参数规模的MoM模型与Transformer不相上下。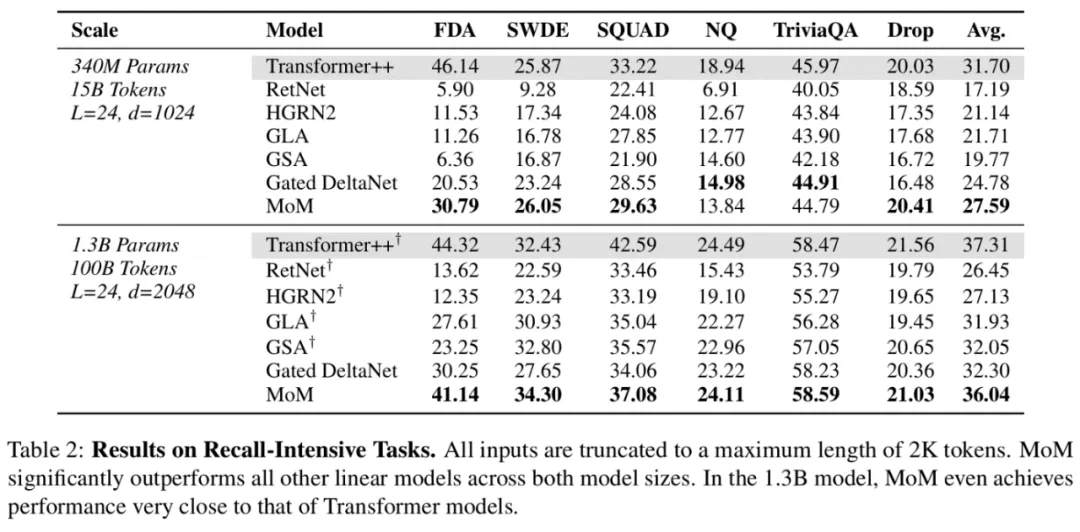

其他评测结果
其他评测结果也相当不错: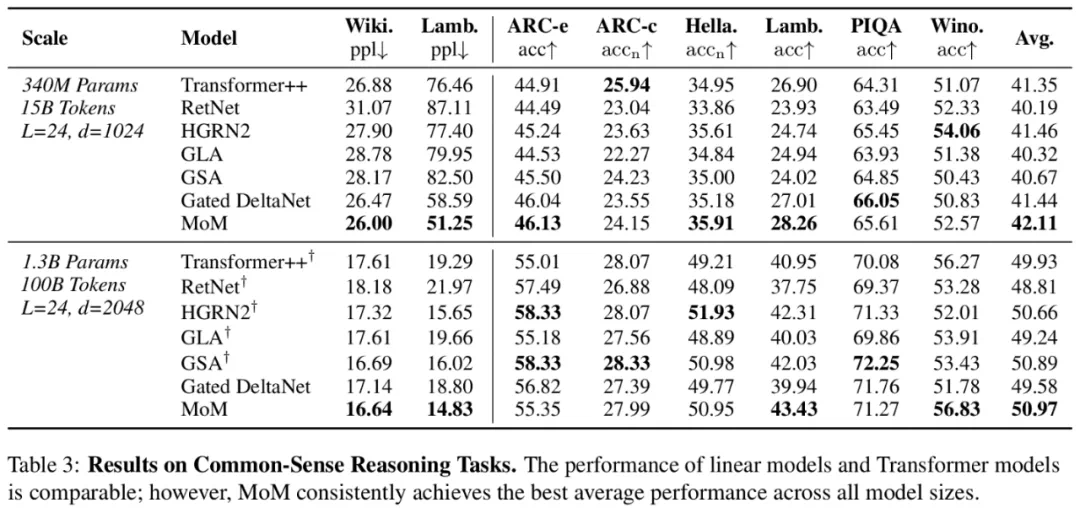

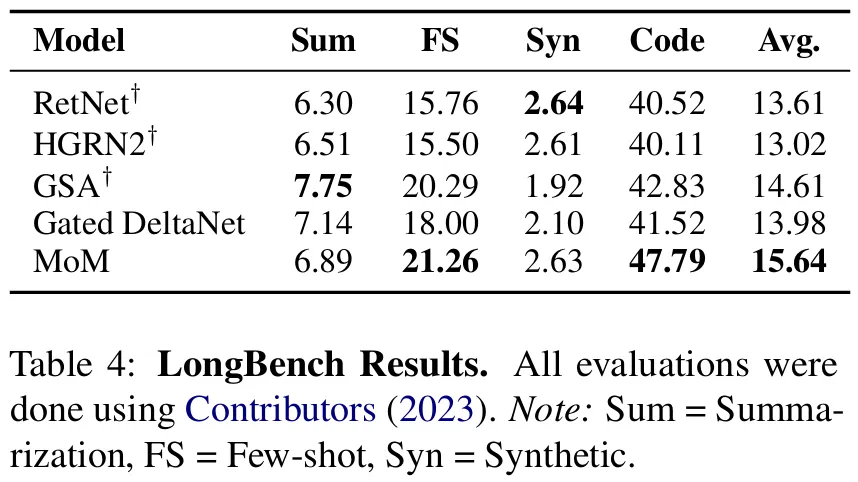

推理效率
推理效率是线性序列建模方法的重点,结果显示MoM在常数级复杂度推理速度和显存占用方面具有显著优势。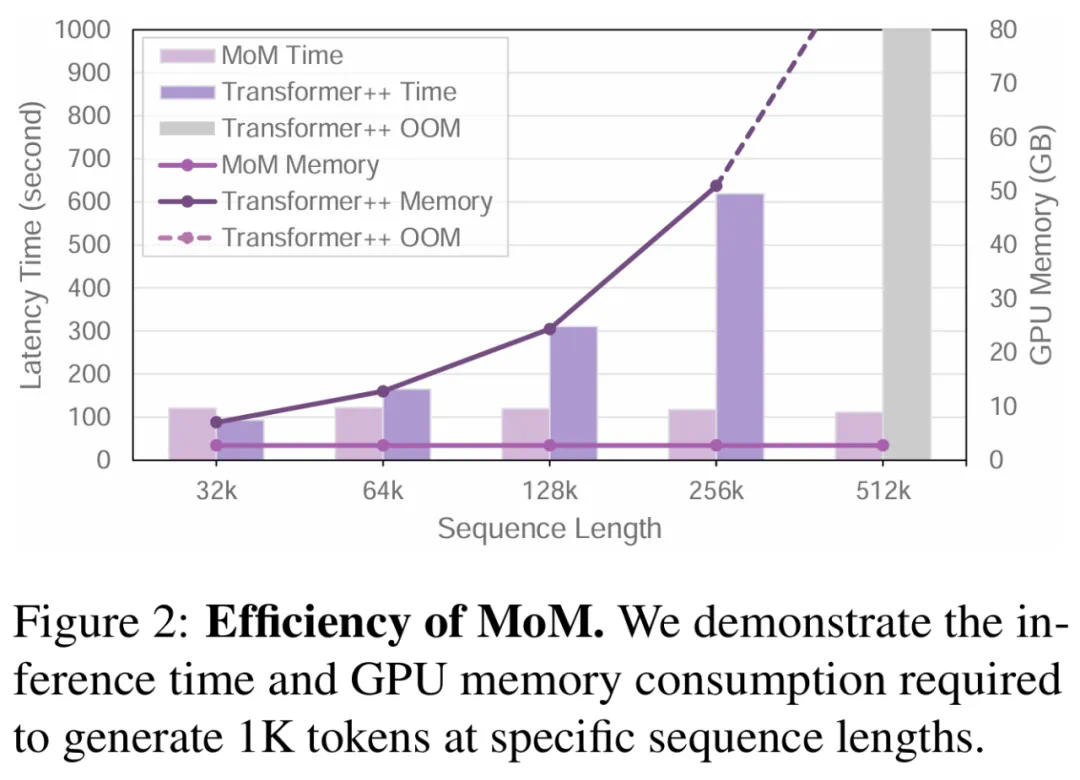

消融实验


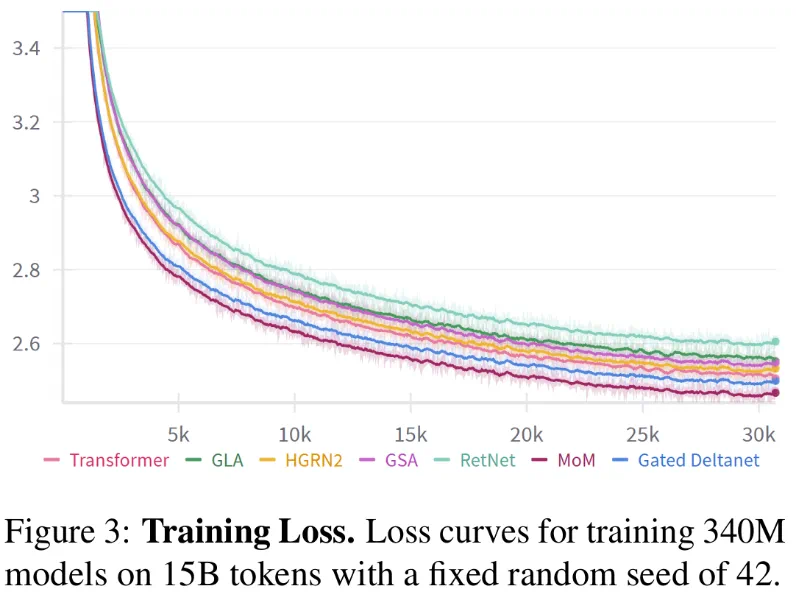
损失曲线

所有图片均保留原始格式和位置。
以上就是上海AI Lab最新推出Mixture-of-Memories:线性注意力也有稀疏记忆了的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/3047898.html

