







目录结构:
contents structure [-]
什么是XML
解析XML
解析XML的两种方式
使用dom4j解析xml
dom4j的部分API
打印一个XML文件的全部内容
在dom4j中应用XPath解析XML
相关的部分API
XPath的路径表达式
通配符
谓语
使用java写一个XMl文件
将一个带有书籍信息的List集合解析为XML文件
Schema和DTD的区别
参考文章
1 什么是XML
XML(eXtensible markup language) 是一种可扩展的标记语言 ,即使可以自定义标签的语言。
2 解析XML
2.1 解析的两种方式
XML的解析分为两种方式,分别是SAX和DOM。
DOM:(Document Object Model,就是文档对象模型),是W3C组织推荐的处理XML的一种方式。使用该方式解析XML文档,会把文档中的所有元素,按照其出现的层次关系,在内存中构造出树形结构。因此对内存的压力大,解析熟读慢,优点就是可以遍历和修改节点的内容。
SAX:(Simple API for XML) 是一种XML解析的替代方法。相比较于DOM,解析速度更快,内存的压力更小;缺点就是不能修改节点的内容。
2.2 使用dom4j解析XML
在使用dom4j解析XML之前需要导入相关的工具包,比如笔者的: dom4j-1.6.1.jar 包
2.2.1 dom4j的API
//创建SAXReader,是dom4j包提供的解析器SAXReader reader=new SAXReader();//读取指定的文件Document doc=reader.read(new File(filename));Document Document getRootElement() 用于获取根元素Element Element element(String name) 获取元素下指定名称的子元素 List elements() 获取元素下所有的子元素 String getName() 获取元素名 String getText() 获取元素文本内容 String elementText(String name) 获取子元素文本内容 Attribute attribute(String) 获取元素的属性 String attributeValue(String name) 获取元素的属性值Attribute String getName() 获取属性的名字 String getValue() 获取属性的值
登录后复制
2.2.2 打印一个XML文件的全部内容
pricties.xml文件直接位于项目下




三国演绎罗贯中58.8 水浒传施耐庵49.8 西游记吴承恩100.11
登录后复制pricties.xml



import java.io.File;import java.util.List;import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.Element;import org.dom4j.io.SAXReader;public class ParseXML {public static void main(String[] args) {//创建SAXReader对象SAXReader saxr=new SAXReader(); Document docu=null;try{//读取指定的文件,相对于项目路径docu=saxr.read(new File("pricties.xml"));//获得元素的文件的根节点Element e=docu.getRootElement(); searchAllElement(e); }catch(Exception e){ e.printStackTrace(); } } public static void searchAllElement(Element e){//获得当前元素下的所有子元素,并存储到集合中List elements=e.elements(); System.out.print("<"+e.getName());//打印开始标记List atrs=e.attributes();//打印该标记下的所有属性for(Attribute att:atrs){ System.out.print(" "+att.getName()+"=""+att.getValue()+"""); } System.out.println(">"); //如果集合的大小为0,表示该集合下没有子元素了if(elements.size()==0){ System.out.println(e.getText());//打印文本信息System.out.println("");//打印结束标记return;//退出当前层方法 } //递归每一个子元素for(Element ele:elements){ searchAllElement(ele); } System.out.println("");//打印结束标记 }}
登录后复制parseXML.xml
2.3 在dom4j中应用XPath解析XML
首先需要在dom4j基础上引入相应的jar包,比如读者的: jaxen-1.1-beta-6.jar
2.3.1 XPath的API
Document List selectNodes(String xpath) Node selectSingleNode(String xpath)
登录后复制
2.3.2 XPath的路径表达式
2.3.2.1 XPath的路径表达式规则
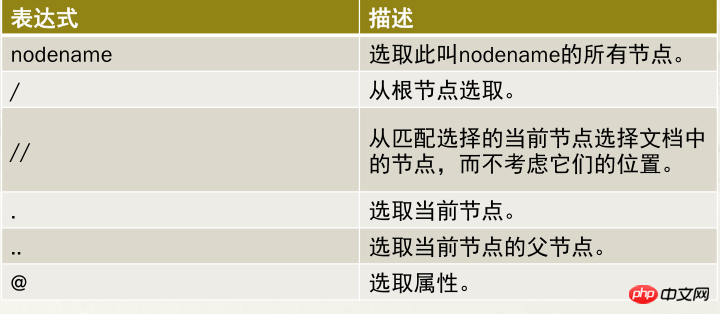

2.3.2.2 XPath的路径表达式应用案例
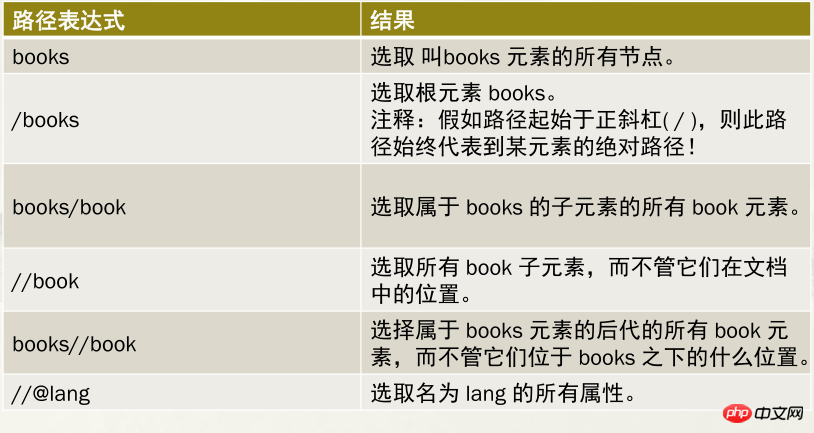

2.3.3 通配符
2.3.3.1 通配符规则


2.3.3.2 通配符应用案例


2.3.4 谓语
2.3.4.1 谓语规则
谓语是用来查找某个特定的节点或是包含某个指定的值的节点
谓语被嵌在方括号中
2.3.4.2 谓语应用案例


3 java写XML文件
3.1 将一个带有书籍信息的List集合解析为XML文件




package com.xdl.xml;public class Book {private String name;private String author;private String price;public Book() {super(); }public Book(String name, String author, String price) {super(); setName(name); setAuthor(author); setPrice(price); }/** * @return the name */public String getName() {return name; }/** * @param name the name to set */public void setName(String name) {this.name = name; }/** * @return the author */public String getAuthor() {return author; }/** * @param author the author to set */public void setAuthor(String author) {this.author = author; }/** * @return the price */public String getPrice() {return price; }/** * @param price the price to set */public void setPrice(String price) {this.price = price; }}
登录后复制Book.java



package com.xdl.xml;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.util.ArrayList;import java.util.List;import org.dom4j.Document;import org.dom4j.DocumentHelper;import org.dom4j.Element;import org.dom4j.io.XMLWriter;public class WriteXML {public static void main(String[] args) {//创建一个Book集合用于存储书籍信息List list_books=new ArrayList();//插入书籍信息for(int i=0;i<6;i++){ Book book=new Book("jame"+i,"author"+i,""+i); list_books.add(book); } //创建一个文档对象Document doc=DocumentHelper.createDocument();//创建一个根节点Element books=DocumentHelper.createElement("books"); //获得书籍集合的大小int size=list_books.size();for(int i=0;i<size;i++){//创建一个book节点Element book=books.addElement("book");//创建一个name节点Element name=book.addElement("name");//创建一个author节点Element author=book.addElement("author");//创建一个price节点Element price=book.addElement("price"); name.setText(list_books.get(i).getName()); author.setText(list_books.get(i).getAuthor()); price.setText(list_books.get(i).getPrice()); }//设置文档根节点 doc.setRootElement(books); try {//如果文件不存在,会自动创建FileOutputStream fos = new FileOutputStream(new File("books.xml")); XMLWriter xmlw = new XMLWriter(fos); xmlw.write(doc); xmlw.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }}
登录后复制WriteXML.java
4 Schema和DTD的区别
Schema是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。DTD的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。它们之间的区别有下面几点:
1、Schema本身也是XML文档,DTD定义跟XML没有什么关系,Schema在理解和实际应用有很多的好处。
2、DTD文档的结构是“平铺型”的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系;Schema文档结构性强,各元素之间的嵌套关系非常直观。
3、DTD只能指定元素含有文本,不能定义元素文本的具体类型,如字符型、整型、日期型、自定义类型等。Schema在这方面比DTD强大。
4、Schema支持元素节点顺序的描述,DTD没有提供无序情况的描述,要定义无序必需穷举排列的所有情况。Schema可以利用xs:all来表示无序的情况。
5、对命名空间的支持。DTD无法利用XML的命名空间,Schema很好满足命名空间。并且,Schema还提供了include和import两种引用命名空间的方法。
5 参考文章
Schema和DTD的区别
以上就是什么是XML?xml的实例讲解的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2491161.html

