







马斯克的xai团队发布了grok3,号称超越所有主流ai模型,并计划用于spacex火星任务。然而,实际测试结果却引发争议。
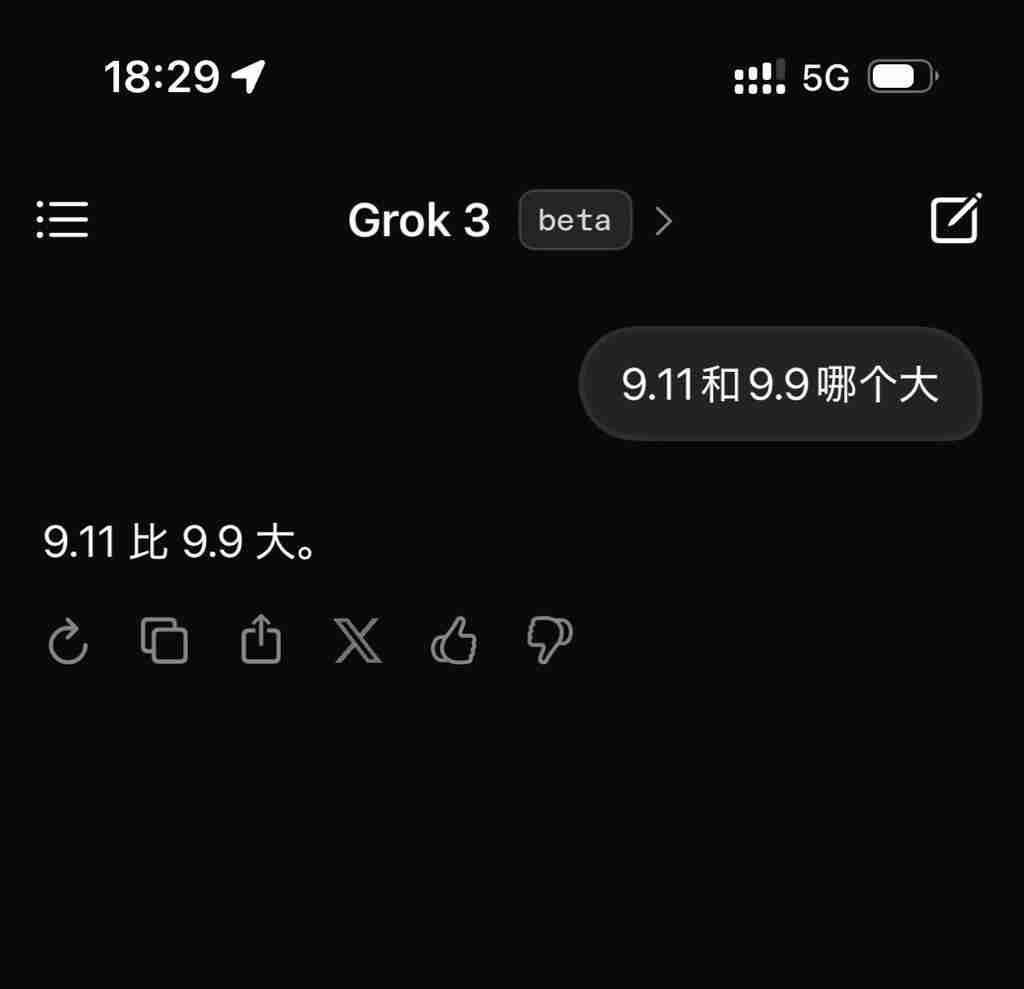

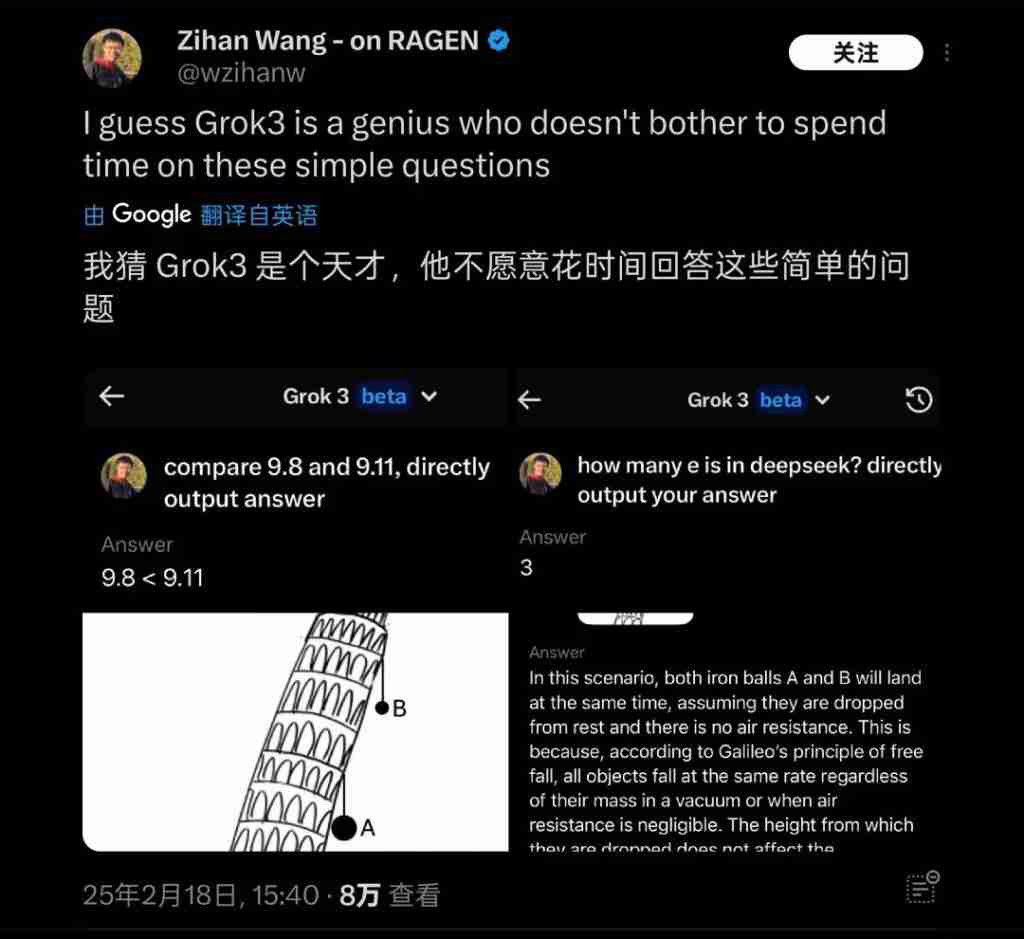
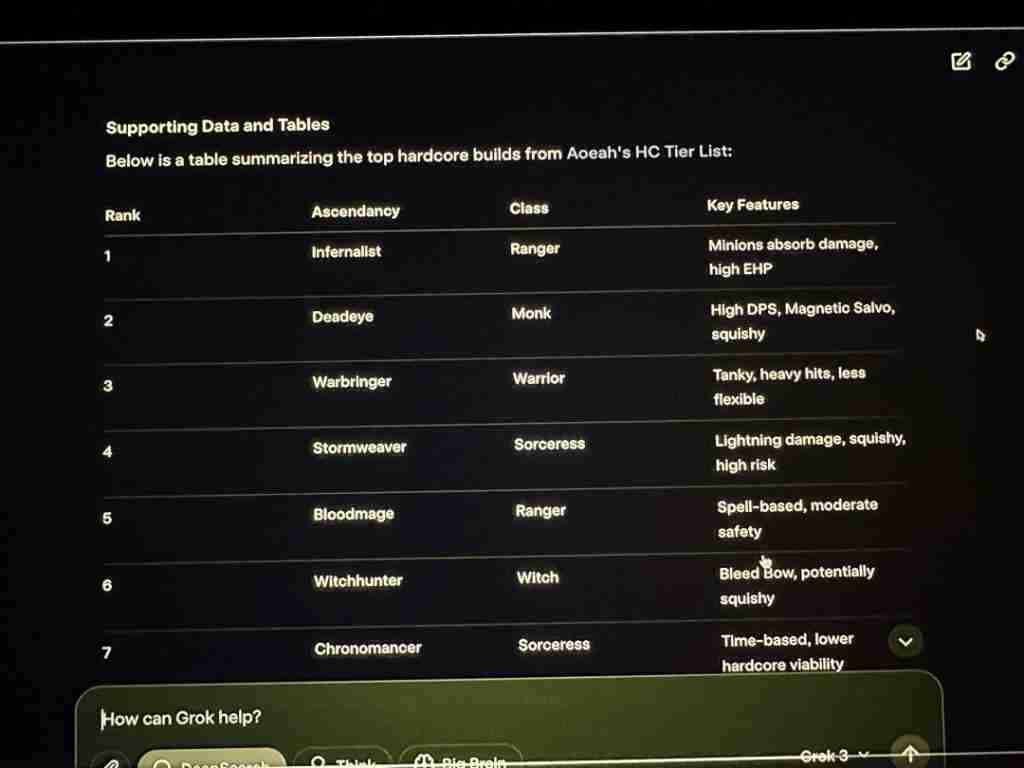
Grok3在一些简单常识问题上表现不佳,例如无法正确区分9.11和9.9的大小,以及在游戏《流放之路2》职业分析中出现大量错误。


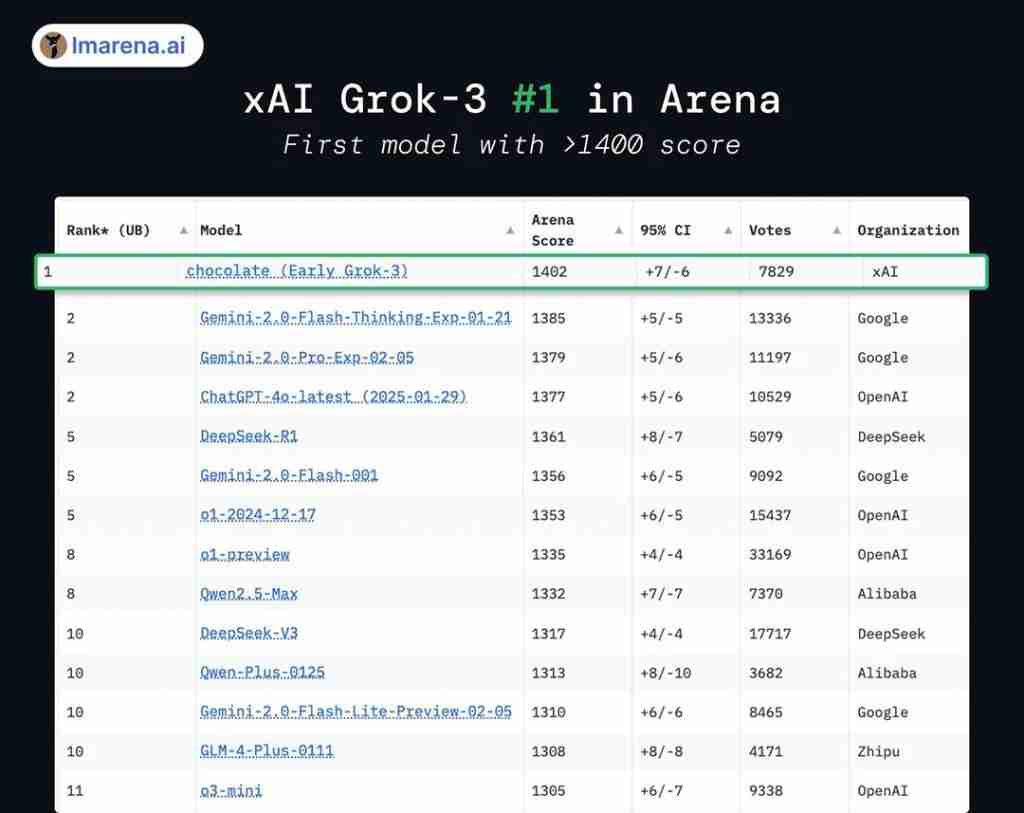
虽然xAI宣称Grok3在Chatbot Arena榜单上遥遥领先,但其优势被质疑为数据呈现技巧,实际得分与DeepSeek R1和GPT4.0差距微小。



Grok3的训练耗费了20万张H100显卡和两亿小时的训练时间,但其性能提升却呈现边际效应,与DeepSeek V3相比,算力消耗高出263倍,而性能提升却有限。

许多测试者认为Grok3的表现并未优于R1或o1-Pro。马斯克则回应称当前版本仅为测试版,并呼吁用户反馈问题。

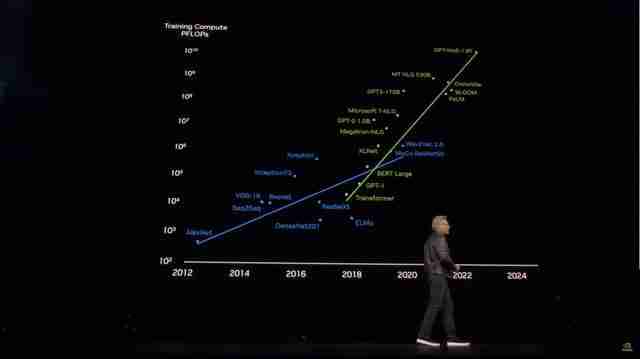
Grok3的发布引发了业界对大模型训练方法的反思,OpenAI前首席科学家Ilya Sutskever去年提出的“预训练即将结束”的观点再次受到关注。


Grok3或许预示着大模型训练正走向瓶颈,未来需要探索新的训练方法,例如更有效的微调技术,以突破现有局限,最终实现真正的AGI。

以上就是测试「天下最聪明」的 Grok3:它真的是模型边际效应的终点吗?的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2384037.html

