







想法是:
给定一个大型虚拟 csv(100 万行)包含客户数据样本,并按照以下目标进行处理:
从 csv 中提取数据计算有多少数据/行对每个城市的客户数量进行分组按客户数量从高到低对城市进行排序计算处理时间
客户的 csv 示例可以在此处下载 https://github.com/datablist/sample-csv-files
加载和提取数据
显然 go 有用于 csv 处理的标准库。我们不再需要第三方依赖来解决我们的问题,这很好。所以解决方案非常简单:
// open the file to a reader interface c, err := os.open("../data/customers-1000000.csv") if err != nil { log.fatal(err) } defer c.close() // load file reader into csv reader // need to set fieldsperrecord to -1 to skip fields checking r := csv.newreader(c) r.fieldsperrecord = -1 r.reuserecord = true records, err := r.readall() if err != nil { log.fatal(err) }
登录后复制从给定路径打开文件将打开的文件加载到 csv 阅读器将所有提取的 csv 记录/行值保存到记录切片中以供以后处理
fieldsperrecord 设置为 -1,因为我想跳过行上的字段检查,因为每种格式的字段或列数可能不同
在此状态下,我们已经能够从 csv 加载和提取所有数据,并准备好进入下一个处理状态。我们还可以使用函数 len(records) 知道 csv 中有多少行。
将总客户分组到每个城市
现在我们可以迭代记录并创建包含城市名称和总客户的地图,如下所示:
["jakarta": 10, "bandung": 200, ...]
登录后复制
csv 行中的城市数据位于第 7 个索引,代码如下所示
// create hashmap to populate city with total customers based on the csv data rows // hashmap will looks like be ["city name": 100, ...] m := map[string]int{} for i, record := range records { // skip header row if i == 0 { continue } if _, found := m[record[6]]; found { m[record[6]]++ } else { m[record[6]] = 1 } }
登录后复制
如果城市地图不存在,则创建新地图并将客户总数设置为1。否则只需增加给定城市的总数。
现在我们的地图 m 包含城市的集合以及其中有多少客户。至此我们已经解决了每个城市有多少客户的分组问题。
对总客户数进行排序
我试图找到标准库中是否有任何函数可以对地图进行排序,但不幸的是我找不到它。排序仅适用于切片,因为我们可以根据索引位置重新排列数据顺序。所以,是的,让我们从当前的地图中切出一个切片。
// convert to slice first for sorting purposesdc := []citydistribution{}for k, v := range m { dc = append(dc, citydistribution{city: k, customercount: v})}
登录后复制
现在我们如何按 customercount 从最高到最低排序?最常见的算法是使用气泡空头。虽然它不是最快的,但它可以完成这项工作。
冒泡排序是最简单的排序算法,如果相邻元素的顺序错误,它的工作原理是重复交换相邻元素。该算法不适合大型数据集,因为其平均和最坏情况时间复杂度相当高。
参考:https://www.geeksforgeeks.org/bubble-sort-algorithm/
使用我们的切片,它将循环数据并检查索引的下一个值,如果当前数据小于下一个索引,则交换它。详细算法可以在参考网站查看。
现在我们的排序过程可能是这样的
// use bubble sortdccount := len(dc)for i := 0; i < dccount; i++ { swapped := false for j := 0; j < dccount-i-1; j++ { if dc[j].customercount < dc[j+1].customercount { temp := dc[j] dc[j] = dc[j+1] dc[j+1] = temp swapped = true } } if !swapped { break }}
登录后复制
循环结束时,最后的切片将为我们提供排序后的数据。
计算处理时间
计算处理时间非常简单,我们获取执行程序主进程之前和之后的时间戳并计算差值。在 go 中,方法应该足够简单:
func main() { start := time.now() // start timing for processing time // the main process // ... duration := time.since(start) fmt.println("processing time (ms): ", duration.milliseconds())}
登录后复制
结果
使用命令运行程序
go run main.go
登录后复制
打印出来的是行数、排序数据和处理时间。像下面这样:
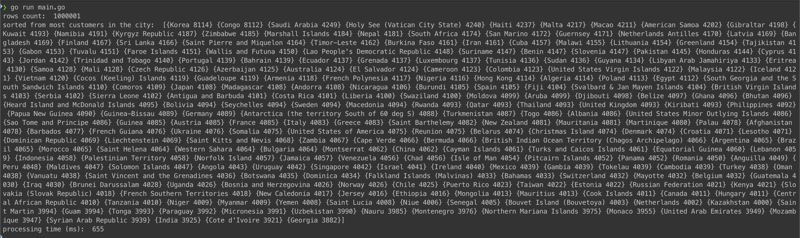
正如 go 性能所预期的那样,它在 1 秒内处理了 100 万行 csv!
所有已完成的代码已发布在我的 github 存储库上:
https://github.com/didikz/csv-processing/tree/main/golang
经验教训
go 中的 csv 处理已经在标准库中可用,无需使用第 3 方库处理数据非常简单。面临的挑战是找出如何对数据进行排序,因为需要手动进行
想到什么?
我认为我当前的解决方案可能可以进一步优化,因为我循环提取了 csv 的所有记录来映射,如果我们检查 readall() 源,它还有循环来根据给定的文件读取器创建切片。这样,1 百万行可以为 1 百万数据生成 2 个循环,这不太好。
我想如果我可以直接从文件读取器读取数据,它只需要 1 个循环,因为我可以直接从中创建地图。除了记录切片将在其他地方使用,但在本例中不使用。
我还没有时间弄清楚,但我也认为如果我手动完成会有一些缺点:
可能需要处理更多解析过程中的错误我不确定它会减少多少处理时间来考虑解决方法是否值得
编码快乐!
以上就是使用 Go 处理大型 CSV的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2311289.html






