







一:前言
嘀嘀嘀,上车请刷卡。昨天看到了不错的图片分享网——花瓣,里面的图片质量还不错,所以利用selenium+xpath我把它的妹子的栏目下爬取了下来,以图片栏目名称给文件夹命名分类保存到电脑中。这个妹子主页 是动态加载的,如果想获取更多内容可以模拟下拉,这样就可以更多的图片资源。这种之前爬虫中也做过,但是因为网速不够快所以我就抓了19个栏目,一共500多张美图,也已经很满意了。
先看看效果:


Paste_Image.png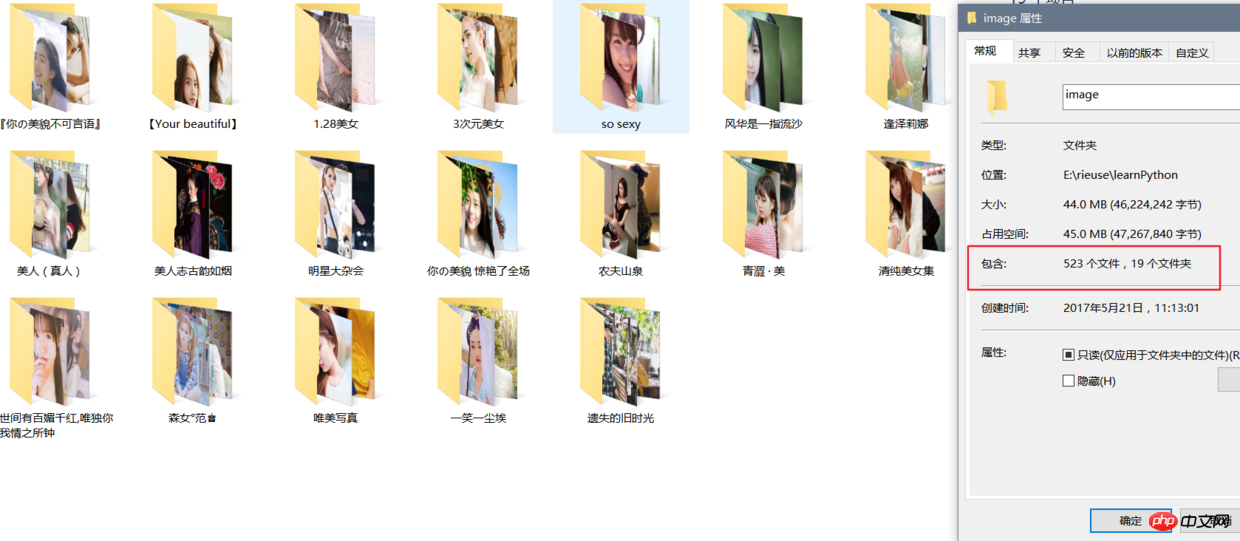

Paste_Image.png
二:运行环境
IDE:Pycharm
Python3.6
lxml 3.7.2
立即学习“Python免费学习笔记(深入)”;
Selenium 3.4.0
requests 2.12.4
三:实例分析
1.这次爬虫我开始做的思路是:进入这个网页然后来获取所有的图片栏目对应网址,然后进入每一个网页中去获取全部图片。(如下图所示)


Paste_Image.png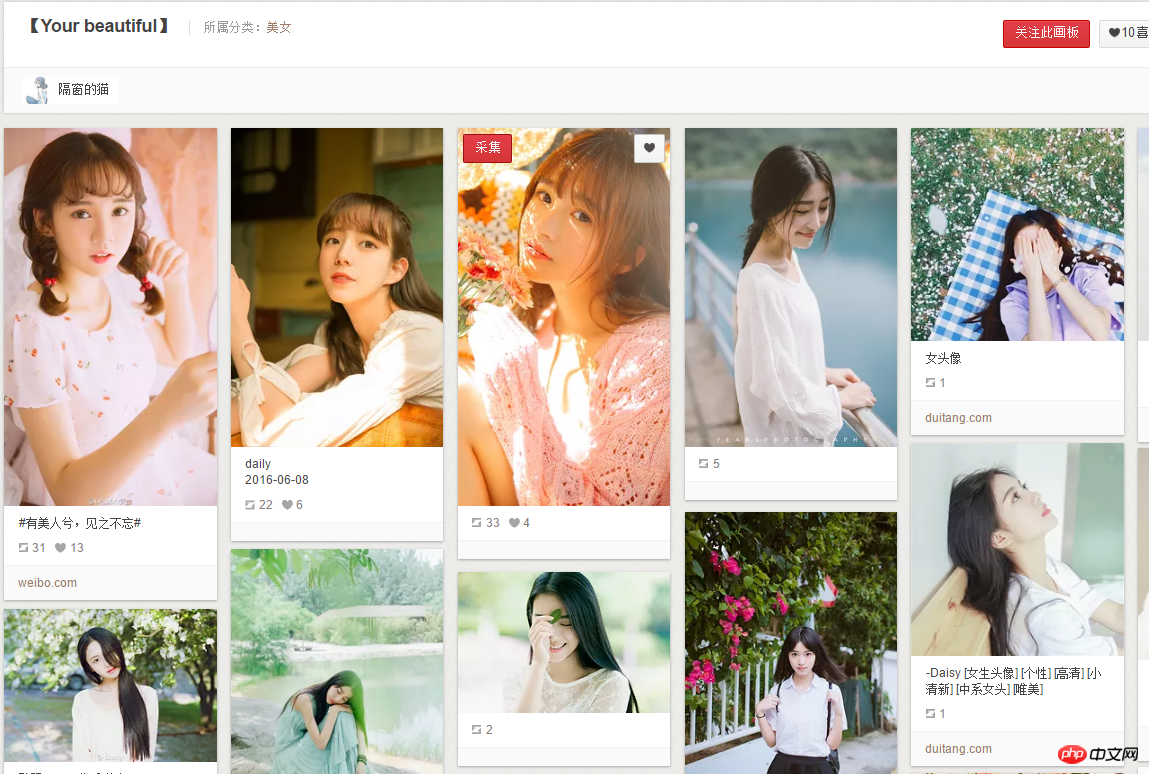

Paste_Image.png
2.但是爬取获取的图片分辨率是236×354,图片质量不够高,但是那个时候已经是晚上1点30之后了,所以第二天做了另一个版本:在这个基础上再进入每个缩略图对应的网页,再抓取像下面这样高清的图片。
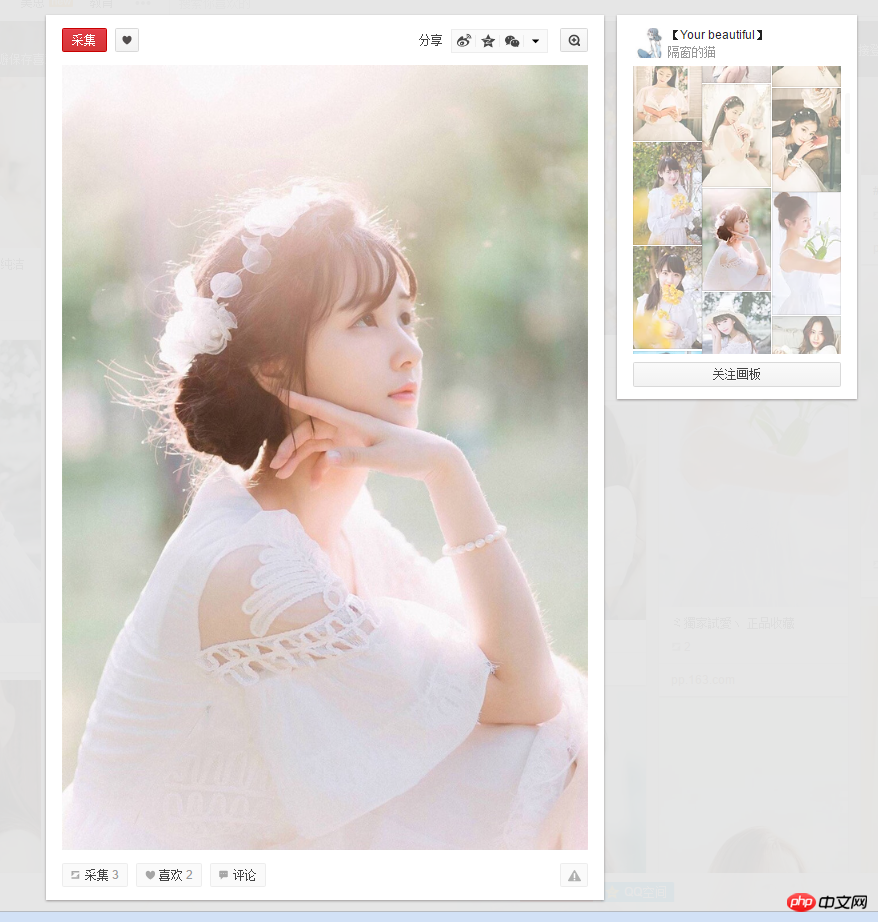

Paste_Image.png
四:实战代码
1.第一步导入本次爬虫需要的模块
__author__ = '布咯咯_rieuse'from selenium.webdriver.common.by import Byfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium import webdriverimport requestsimport lxml.htmlimport os
登录后复制
2.下面是设置webdriver的种类,就是使用什么浏览器进行模拟,可以使用火狐来看它模拟的过程,也可以是无头浏览器PhantomJS来快速获取资源,[‘–load-images=false’, ‘–disk-cache=true’]这个意思是模拟浏览的时候不加载图片和缓存,这样运行速度会加快一些。WebDriverWait标明最大等待浏览器加载为10秒,set_window_size可以设置一下模拟浏览网页的大小。有些网站如果大小不到位,那么一些资源就不加载出来。
# SERVICE_ARGS = ['--load-images=false', '--disk-cache=true']# browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)browser = webdriver.Firefox()wait = WebDriverWait(browser, 10)browser.set_window_size(1400, 900)
登录后复制
3.parser(url, param)这个函数用来解析网页,后面有几次都用用到这些代码,所以直接写一个函数会让代码看起来更整洁有序。函数有两个参数:一个是网址,另一个是显性等待代表的部分,这个可以是网页中的某些板块,按钮,图片等等…
def parser(url, param): browser.get(url) wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, param))) html = browser.page_source doc = lxml.html.fromstring(html)return doc
登录后复制
4.下面的代码就是解析本次主页面 然后获取到每个栏目的网址和栏目的名称,使用xpath来获取栏目的网页时,进入网页开发者模式后,如图所示进行操作。之后需要用栏目名称在电脑中建立文件夹,所以在这个网页中要获取到栏目的名称,这里遇到一个问题,一些名称不符合文件命名规则要剔除,我这里就是一个 * 影响了。
def get_main_url(): print('打开主页搜寻链接中...')try: doc = parser('http://huaban.com/boards/favorite/beauty/', '#waterfall') name = doc.xpath('//*[@id="waterfall"]/div/a[1]/div[2]/h3/text()') u = doc.xpath('//*[@id="waterfall"]/div/a[1]/@href')for item, fileName in zip(u, name): main_url = 'http://huaban.com' + item print('主链接已找到' + main_url)if '*' in fileName: fileName = fileName.replace('*', '') download(main_url, fileName)except Exception as e: print(e)
登录后复制

Paste_Image.png
5.前面已经获取到栏目的网页和栏目的名称,这里就需要对栏目的网页分析,进入栏目网页后,只是一些缩略图,我们不想要这些低分辨率的图片,所以要再进入每个缩略图中,解析网页获取到真正的高清图片网址。这里也有一个地方比较坑人,就是一个栏目中,不同的图片存放dom格式不一样,所以我这样做
img_url = doc.xpath('//*[@id="baidu_image_holder"]/a/img/@src')img_url2 = doc.xpath('//*[@id="baidu_image_holder"]/img/@src')
登录后复制
这就把两种dom格式中的图片地址都获取了,然后把两个地址list合并一下。img_url +=img_url2
在本地创建文件夹使用filename = ‘image{}’.format(fileName) + str(i) + ‘.jpg’表示文件保存在与这个爬虫代码同级目录image下,然后获取的图片保存在image中按照之前获取的栏目名称的文件夹中。
def download(main_url, fileName): print('-------准备下载中-------')try: doc = parser(main_url, '#waterfall')if not os.path.exists('image\' + fileName): print('创建文件夹...') os.makedirs('image\' + fileName) link = doc.xpath('//*[@id="waterfall"]/div/a/@href')# print(link) i = 0for item in link: i += 1 minor_url = 'http://huaban.com' + item doc = parser(minor_url, '#pin_view_page') img_url = doc.xpath('//*[@id="baidu_image_holder"]/a/img/@src') img_url2 = doc.xpath('//*[@id="baidu_image_holder"]/img/@src') img_url +=img_url2try: url = 'http:' + str(img_url[0]) print('正在下载第' + str(i) + '张图片,地址:' + url) r = requests.get(url) filename = 'image\{}\'.format(fileName) + str(i) + '.jpg'with open(filename, 'wb') as fo: fo.write(r.content)except Exception: print('出错了!')except Exception: print('出错啦!')if __name__ == '__main__': get_main_url()
登录后复制
五:总结
这次爬虫继续练习了Selenium和xpath的使用,在网页分析的时候也遇到很多问题,只有不断练习才能把自己不会部分减少,当然这次爬取了500多张妹纸还是挺养眼的。
以上就是利用Python抓取花瓣网美图实例的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2270249.html

