







这篇文章主要介绍了python实现的下载网页源码功能,涉及python基于http请求与响应实现的网页源码读取功能相关操作技巧,需要的朋友可以参考下
本文实例讲述了Python实现的下载网页源码功能。分享给大家供大家参考,具体如下:
#!/usr/bin/pythonimport httplibhttpconn = httplib.HTTPConnection("www.baidu.com")httpconn.request("GET", "/index.html")resp = httpconn.getresponse()if resp.reason == "OK": resp_data = resp.read() print resp_data print len(resp_data)httpconn.close()
登录后复制
要下载的网页源码被读取到了resp_data中了
运行效果图如下:
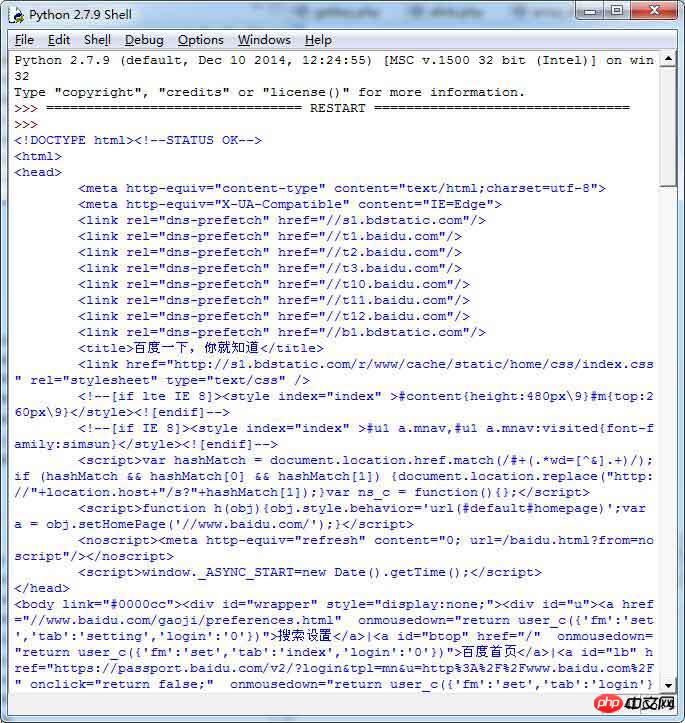

立即学习“Python免费学习笔记(深入)”;
以上就是Python实现网页中下载的功能实例的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2267374.html

