







Excel的基本组成
我们一般在最开始做报表的时候,基本都是从excel开始的,都是利用excel在做报表,所以我们先了解下excel的基本组成。
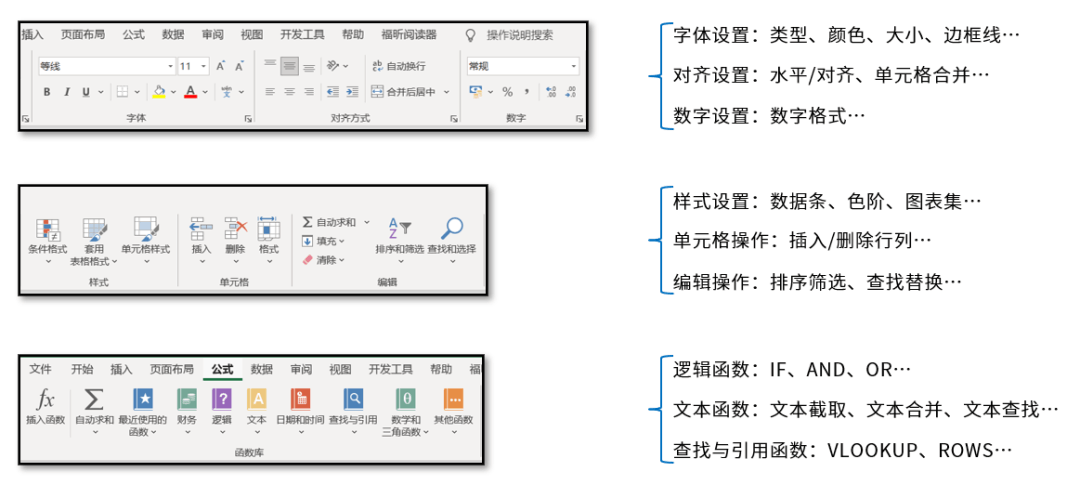
下图是Excel的中各个部分的组成关系,我们工作中每天会处理很多Excel文件,一个Excel文件其实就是一个工作簿。每次新建一个Excel文件时,文件名默认为工作簿x,其中x表示新建的文件个数。一个工作簿可以包含多个Sheet,每个Sheet都是一个独立的表格。每一个Sheet里面又由若干个单元格组成。每一个单元格又有若干的元素或属性,我们一般针对Excel文件进行设置最多的其实就是针对单元格的元素进行设置。


主要针对单元格元素设置的内容包括菜单栏中显示的内容,例如字体、对齐方式、条件格式等。本书也是按照Excel菜单栏中的各个模块进行编写。

立即学习“Python免费学习笔记(深入)”;
一份自动化报表的流程
下图是我整理的做一份自动化报表需要经历的流程,主要分为5个步骤:
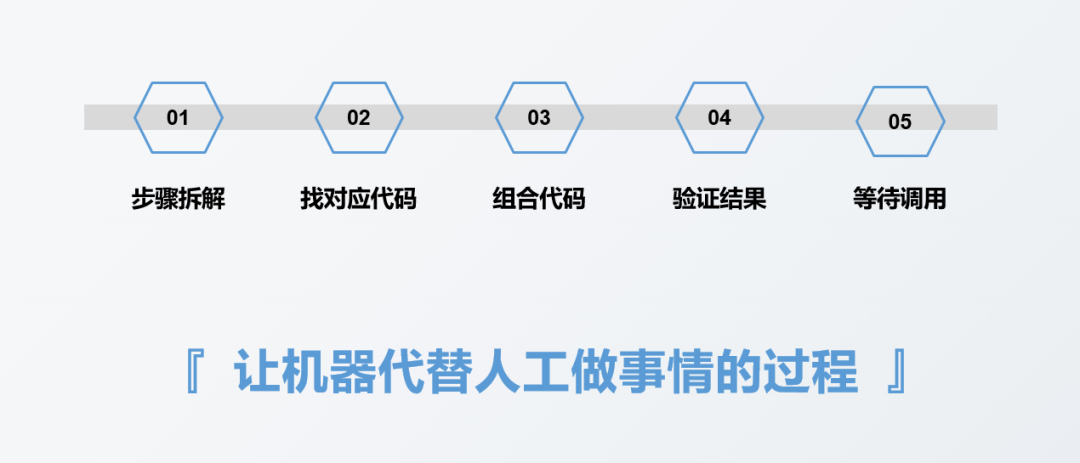

第一步是对要做的报表进行步骤拆解,这个步骤拆解和用不用工具或者是用什么工具没有直接关系,比如做报表的第一步一般都是收集数据,这个数据可能是线下人员记录在纸质笔记本上的,也可能是存储在Excel表里面的,还有可能是存储在数据库里面的。会因为数据源的类型或者是存储方式不同,对应的收集数据方式会不一样,但是收集数据这个步骤本身是不会变的,这个步骤的目的就是把数据收集过来。
第二步是去想第一步里面涉及到的每一个具体步骤对应的代码实现方式,一般都是去找对应每一步的代码,比如导入数据的代码是什么样的,再比如重复值删除的代码是什么样的。
第三步是将第二步中各个步骤对应的代码进行组合,组合成一个完整的代码。
第四步是对第三步完整代码得出来的报表结果进行验证,看结果是否正确。
第五步就是等待调用,看什么时候需要制作报表了,然后就将写好的代码执行一遍就行。
其实报表自动化本质上就是让机器代替人工做事情的过程,我们只需要把我们人工需要做的每一个步骤转化成机器可以理解的语言,也就是代码,然后让机器自动去执行,这其实就是实现了自动化。
报表自动化实战
这一节给大家演示下在实际工作中如何结合Pandas和openpyxl来自动化生成报表。
假设我们现在有如下一份数据集:
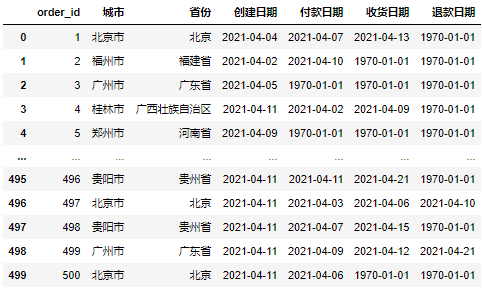

现在我们需要根据这份数据集来制作每天的日报情况,会主要包含三方面:
当日各项指标的同环比情况;
当日各省份创建订单量情况;
最近一段时间创建订单量趋势
接下来分别来实现这三部分。
当日各项指标的同环比情况
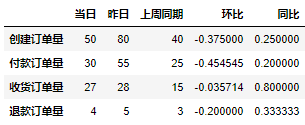
我们先用Pandas对数据进行计算处理,得到各指标的同环比情况,具体实现代码如下:
#导入文件import pandas as pddf = pd.read_excel(r'D:Data-Scienceshareexcel-python报表自动化sale_data.xlsx')#构造同时获取不同指标的函数def get_data(date): create_cnt = df[df['创建日期'] == date]['order_id'].count() pay_cnt = df[df['付款日期'] == date]['order_id'].count() receive_cnt = df[df['收货日期'] == date]['order_id'].count() return_cnt = df[df['退款日期'] == date]['order_id'].count() return create_cnt,pay_cnt,receive_cnt,return_cnt #假设当日是2021-04-11#获取不同时间段的各指标值df_view = pd.DataFrame([get_data('2021-04-11') ,get_data('2021-04-10') ,get_data('2021-04-04')] ,columns = ['创建订单量','付款订单量','收货订单量','退款订单量'] ,index = ['当日','昨日','上周同期']).Tdf_view['环比'] = df_view['当日'] / df_view['昨日'] - 1df_view['同比'] = df_view['当日'] / df_view['上周同期'] - 1df_view
登录后复制
运行上面代码会得到如下结果:

上面只是得到了各指标的同环比绝对数值,但是我们一般的日报在发出去之前都要做一些格式调整的,比如调整字体之类的。而格式调整就需要用到openpyxl库,我们需要将Pandas库中DataFrame格式的数据转化为适用openpyxl库的数据格式,具体实现代码如下:
from openpyxl import Workbookfrom openpyxl.utils.dataframe import dataframe_to_rows#创建空工作簿wb = Workbook()ws = wb.active#将DataFrame格式数据转化为openpyxl格式for r in dataframe_to_rows(df_view,index = True,header = True): ws.append(r)wb.save(r'D:Data-Scienceshareexcel-python报表自动化核心指标_原始.xlsx')
登录后复制
运行上面代码会得到如下结果,可以看到原始的数据文件看起来是很混乱的:

接下来我们针对上面原始数据文件进行格式调整,具体调整代码如下:
from openpyxl import Workbookfrom openpyxl.utils.dataframe import dataframe_to_rowsfrom openpyxl.styles import colorsfrom openpyxl.styles import Fontfrom openpyxl.styles import PatternFillfrom openpyxl.styles import Border, Sidefrom openpyxl.styles import Alignmentwb = Workbook()ws = wb.activefor r in dataframe_to_rows(df_view,index = True,header = True): ws.append(r) #第二行是空的,删除第二行ws.delete_rows(2)#给A1单元格进行赋值ws['A1'] = '指标'#插入一行作为标题行ws.insert_rows(1)ws['A1'] = '电商业务方向 2021/4/11 日报'#将标题行的单元格进行合并ws.merge_cells('A1:F1') #合并单元格#对第1行至第6行的单元格进行格式设置for row in ws[1:6]: for c in row: #字体设置 c.font = Font(name = '微软雅黑',size = 12) #对齐方式设置 c.alignment = Alignment(horizontal = "center") #边框线设置 c.border = Border(left = Side(border_style = "thin",color = "FF000000"), right = Side(border_style = "thin",color = "FF000000"), top = Side(border_style = "thin",color = "FF000000"), bottom = Side(border_style = "thin",color = "FF000000"))#对标题行和表头行进行特殊设置for row in ws[1:2]: for c in row: c.font = Font(name = '微软雅黑',size = 12,bold = True,color = "FFFFFFFF") c.fill = PatternFill(fill_type = 'solid',start_color='FFFF6100')#将环比和同比设置成百分比格式 for col in ws["E":"F"]: for r in col: r.number_format = '0.00%'#调整列宽ws.column_dimensions['A'].width = 13ws.column_dimensions['E'].width = 10#保存调整后的文件 wb.save(r'D:Data-Scienceshareexcel-python报表自动化核心指标.xlsx')
登录后复制
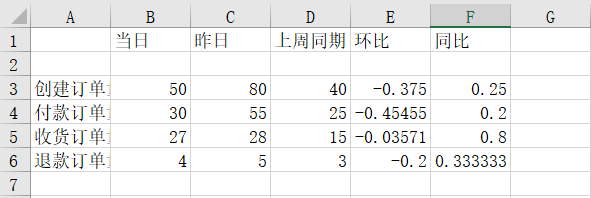
运行上面代码会得到如下结果:


可以看到各项均已设置成功。
当日各省份创建订单量情况
df_province = pd.DataFrame(df[df['创建日期'] == '2021-04-11'].groupby('省份')['order_id'].count())df_province = df_province.reset_index()df_province = df_province.sort_values(by = 'order_id',ascending = False)df_province = df_province.rename(columns = {'order_id':'创建订单量'})df_province
登录后复制
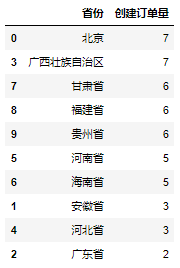
我们同样先利用Pandas库处理得到当日各省份创建订单量情况,具体实现代码如下:
运行上面代码会得到如下结果:

在得到各省份当日创建订单量的绝对数值之后,同样对其进行格式设置,具体设置代码如下:
from openpyxl import Workbookfrom openpyxl.utils.dataframe import dataframe_to_rowsfrom openpyxl.styles import colorsfrom openpyxl.styles import Fontfrom openpyxl.styles import PatternFillfrom openpyxl.styles import Border, Sidefrom openpyxl.styles import Alignmentfrom openpyxl.formatting.rule import DataBarRulewb = Workbook()ws = wb.activefor r in dataframe_to_rows(df_province,index = False,header = True): ws.append(r)#对第1行至第11行的单元格进行设置for row in ws[1:11]: for c in row: #字体设置 c.font = Font(name = '微软雅黑',size = 12) #对齐方式设置 c.alignment = Alignment(horizontal = "center") #边框线设置 c.border = Border(left = Side(border_style = "thin",color = "FF000000"), right = Side(border_style = "thin",color = "FF000000"), top = Side(border_style = "thin",color = "FF000000"), bottom = Side(border_style = "thin",color = "FF000000"))#设置进度条条件格式rule = DataBarRule(start_type = 'min',end_type = 'max', color="FF638EC6", showValue=True, minLength=None, maxLength=None)ws.conditional_formatting.add('B1:B11',rule)#对第1行标题行进行设置for c in ws[1]: c.font = Font(name = '微软雅黑',size = 12,bold = True,color = "FFFFFFFF") c.fill = PatternFill(fill_type = 'solid',start_color='FFFF6100') #调整列宽ws.column_dimensions['A'].width = 17ws.column_dimensions['B'].width = 13#保存调整后的文件 wb.save(r'D:Data-Scienceshareexcel-python报表自动化各省份销量情况.xlsx')
登录后复制
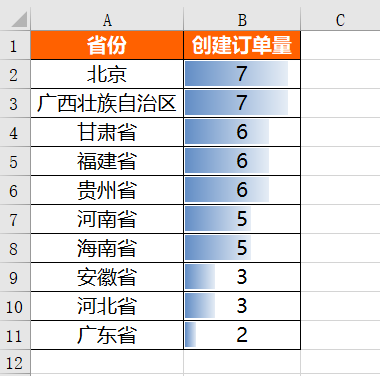
运行上面代码会得到如下结果:

最近一段时间创建订单量趋势
一般用折线图的形式反映某个指标的趋势情况,我们前面也讲过,在实际工作中我们一般用matplotlib或者其他可视化的库进行图表绘制,并将其进行保存,然后再利用openpyxl库将图表插入到Excel中。
先利用matplotlib库进行绘图,具体实现代码如下:
%matplotlib inlineimport matplotlib.pyplot as pltplt.rcParams["font.sans-serif"]='SimHei'#解决中文乱码#设置图表大小plt.figure(figsize = (10,6))df.groupby('创建日期')['order_id'].count().plot()plt.title('4.2 - 4.11 创建订单量分日趋势')plt.xlabel('日期')plt.ylabel('订单量')#将图表保存到本地plt.savefig(r'D:Data-Scienceshareexcel-python报表自动化.2 - 4.11 创建订单量分日趋势.png')
登录后复制
将保存到本地的图表插入到Excel中,具体实现代码如下:
from openpyxl import Workbookfrom openpyxl.drawing.image import Imagewb = Workbook()ws = wb.activeimg = Image(r'D:Data-Scienceshareexcel-python报表自动化.2 - 4.11 创建订单量分日趋势.png')ws.add_image(img, 'A1')wb.save(r'D:Data-Scienceshareexcel-python报表自动化.2 - 4.11 创建订单量分日趋势.xlsx')
登录后复制
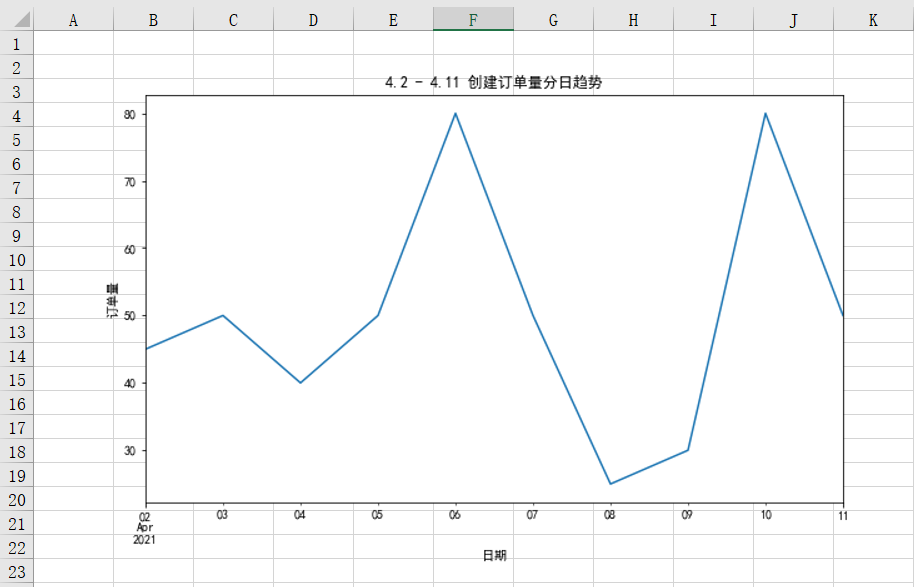
运行上面代码会得到如下结果,可以看到图表已经被成功插入到Excel中:

将不同的结果进行合并
我们将每个部分单独实现后,将其存储在不同的Excel文件中。当然了,有的时候放在不同文件中会比较麻烦,我们就需要把这些结果合并在同一个Excel的相同Sheet或者不同Sheet中。
将不同的结果合并到同一个Sheet中:
合并不同表结果到同一个Sheet中的挑战在于它们的结构不同,同时需要添加适当的间隔来区分不同的结果。
首先插入核心指标表df_review,插入方式与单独的插入是一样的,具体代码如下:
for r in dataframe_to_rows(df_view,index = True,header = True): ws.append(r)
登录后复制
接下来就该插入各省份情况表df_province,因为append默认是从第一行开始插入的,而我们前面几行已经有df_view表的数据了,所以就不能用appen的方式进行插入,而只能通过遍历每一个单元格的方式进行插入。
那我们怎么知道要遍历哪些单元格呢?核心需要知道遍历开始的行列和遍历结束的行列。
遍历开始的行 = df_view表占据的行 + 留白的行(一般表与表之间留2行) + 1遍历结束的行 = 遍历开始的行 + df_province表占据的行遍历开始的列 = 1遍历结束的列 = df_province表占据的列
而又因为DataFrame中获取列名的方式和获取具体值的方式不太一样,所以我们需要分别插入,先插入列名,具体代码如下:
for j in range(df_province.shape[1]): ws.cell(row = df_view.shape[0] + 5,column = 1 + j).value = df_province.columns[r]
登录后复制
df_province.shape[1]是获取df_province表有多少列,df_view.shape[0]是获取df_view表有多少行。
前面说过,遍历开始的行是表占据的行加上留白的行再加1,一般留白的行是2,可是这里面为啥是df_view.shape[0] + 5呢?这是因为df_view.shape[0]是不包列名行的,同时在插入Excel中的时候会默认增加1行空行,所以就需要在留白行的基础上再增加2行,即2 + 2 + 1 = 5。
由于Excel中的列从1开始计数,而range()函数默认从0开始,因此需要给column加1。
上面的代码只是把df_province表的列名插入进来了,接下来插入具体的值,方式与插入列名的方式一致,只不过需要在列名的下一行开始插入,具体代码如下:
接下来就该插入图片了,插入图片的方式与前面单独的插入是一致的,具体代码如下:
#再把具体的值插入for i in range(df_province.shape[0]): for j in range(df_province.shape[1]): ws.cell(row = df_view.shape[0] + 6 + i,column = 1 + j).value = df_province.iloc[i,j]
登录后复制
将所有的数据插入以后就该对这些数据进行格式设置了,因为不同表的结构不一样,所以我们没法直接批量针对所有的单元格进行格式设置,只能分范围分别进行设置,而不同范围的格式可能是一样的,所以我们先预设一些格式变量,这样后面用到的时候直接调取这些变量即可,减少代码冗余,具体代码如下:
#插入图片img = Image(r'D:Data-Scienceshareexcel-python报表自动化.2 - 4.11 创建订单量分日趋势.png')ws.add_image(img, 'G1')
登录后复制
格式预设完之后就可以对各个范围分别进行格式设置了,具体代码如下:
#格式预设#表头字体设置title_Font_style = Font(name = '微软雅黑',size = 12,bold = True,color = "FFFFFFFF")#普通内容字体设置plain_Font_style = Font(name = '微软雅黑',size = 12)Alignment_style = Alignment(horizontal = "center")Border_style = Border(left = Side(border_style = "thin",color = "FF000000"), right = Side(border_style = "thin",color = "FF000000"), top = Side(border_style = "thin",color = "FF000000"), bottom = Side(border_style = "thin",color = "FF000000"))PatternFill_style = PatternFill(fill_type = 'solid',start_color='FFFF6100')
登录后复制
最后将上面所有代码片段合并在一起,就是将不同的结果文件合并到同一个Sheet中的完整代码,具体结果如下,可以看到不同结果文件合并在了一起,并且各自的格式设置完好。
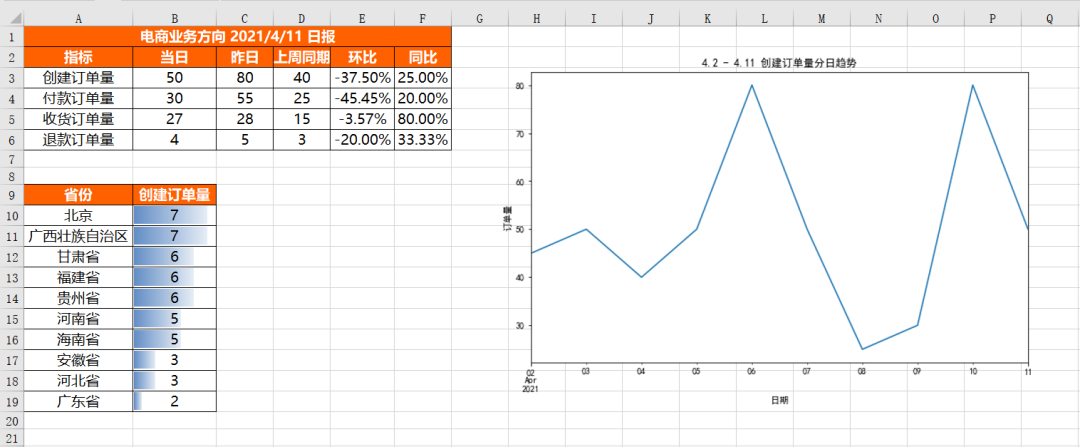

将不同的结果合并到同一工作簿的不同Sheet中:
将不同的结果合并到同一工作簿的不同Sheet中比较好实现,只需要新建几个Sheet,然后针对不同的Sheet插入数据即可,具体实现代码如下:
from openpyxl import Workbookfrom openpyxl.utils.dataframe import dataframe_to_rowswb = Workbook()ws = wb.activews1 = wb.create_sheet()ws2 = wb.create_sheet()#更改sheet的名称ws.title = "核心指标" ws1.title = "各省份销情况" ws2.title = "分日趋势" for r1 in dataframe_to_rows(df_view,index = True,header = True): ws.append(r1)for r2 in dataframe_to_rows(df_province,index = False,header = True): ws1.append(r2)img = Image(r'D:Data-Scienceshareexcel-python报表自动化.2 - 4.11 创建订单量分日趋势.png')ws2.add_image(img, 'A1')wb.save(r'D:Data-Scienceshareexcel-python报表自动化多结果合并_多Sheet.xlsx')
登录后复制
运行上面代码,会得到如下结果,可以看到创建了3个Sheet,且不同的内容保存到了不同Sheet中:
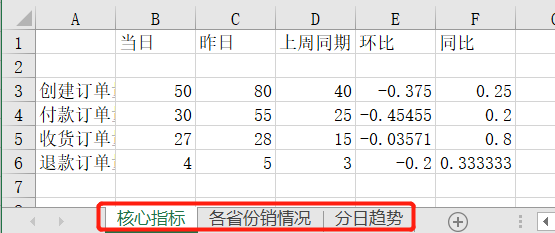

到这里我们的一份自动化报表的代码就完成了,以后每次需要用到这份报表的时候,把上面代码执行一遍,结果马上就可以出来,当然了也可以设置定时执行,到时间结果就自动发送到你邮箱里面啦。
以上就是怎么用Python实现报表自动化的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2235229.html

