







此博客最初发布到 crawlbase 博客
高效、快速的代码对于在软件应用程序中创建出色的用户体验非常重要。用户不喜欢等待缓慢的响应,无论是加载网页、训练机器学习模型还是运行脚本。加快代码速度的一种方法是缓存。
缓存的目的是临时缓存经常使用的数据,以便您的程序可以更快地访问它,而不必多次重新计算或检索它。缓存可以加快响应时间、减少负载并改善用户体验。
本博客将介绍缓存原理、其作用、用例、策略以及 python 中缓存的实际示例。让我们开始吧!
在 python 中实现缓存
在 python 中可以通过多种方式进行缓存。我们来看两种常见的方法:使用手动装饰器进行缓存和python内置的functools.lru_cache。
立即学习“Python免费学习笔记(深入)”;
1. 用于缓存的手动装饰器
装饰器是一个包装另一个函数的函数。我们可以创建一个缓存装饰器,将函数调用的结果存储在内存中,并在再次调用相同的输入时返回缓存的结果。这是一个例子:
import requests# manual caching decoratordef memoize(func): cache = {} def wrapper(*args): if args in cache: return cache[args] result = func(*args) cache[args] = result return result return wrapper# function to get data from a url@memoizedef get_html(url): response = requests.get(url) return response.text# example usageprint(get_html('https://crawlbase.com'))
登录后复制
在此示例中,第一次调用 get_html 时,它会从 url 获取数据并缓存。在使用相同 url 的后续调用中,将返回缓存的结果。
使用python的functools.lru_cache
python 在 functools 模块中提供了一个名为 lru_cache 的内置缓存机制。该装饰器会缓存函数调用,并在缓存已满时删除最近最少使用的项目。使用方法如下:
from functools import lru_cache@lru_cache(maxsize=128)def expensive_computation(x, y): return x * y# Example usageprint(expensive_computation(5, 6))
登录后复制
在这个例子中,lru_cache缓存了expense_computation的结果。如果使用相同的参数再次调用该函数,它将返回缓存的结果而不是重新计算。
缓存策略的性能比较
选择缓存策略时,需要考虑它们在不同条件下的表现。缓存策略的性能取决于缓存命中数(当在缓存中找到数据时)和缓存的大小。
以下是常见缓存策略的比较:
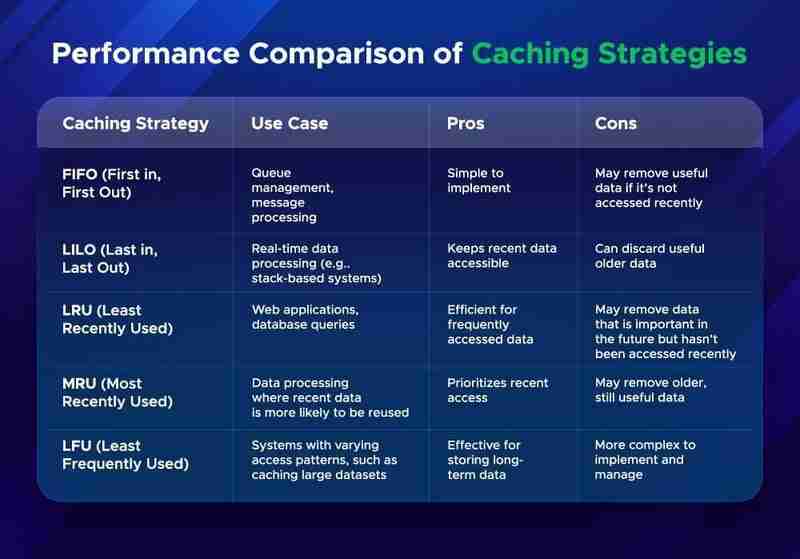

选择正确的缓存策略取决于应用程序的数据访问模式和性能需求。
最后的想法
缓存对于您的应用程序非常有用。它可以减少数据检索时间和系统负载。无论您是在构建网络应用程序、机器学习项目还是想要加快系统速度,智能缓存都可以让您的代码运行得更快。
诸如 fifo、lru 和 lfu 之类的缓存方法有不同的用例。例如,lru 适用于需要保留频繁访问的数据的 web 应用程序,而 lfu 适用于需要随时间存储数据的程序。
正确实施缓存将使您设计出更快、更高效的应用程序,并获得更好的性能和用户体验。
以上就是Python 缓存:如何通过有效的缓存来加速代码的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2175812.html

