







探秘advent of code第三天的解析挑战:优雅地处理杂乱输入
最近重温Advent of Code第三天的挑战,它巧妙地提出了一个有趣的解析问题:从杂乱的输入中提取有效代码。这对于解析器和词法分析器开发来说是一次绝佳的练习。让我们一起探索解决这个问题的策略。

起初,我依赖hy进行解析。但最近对生成式AI的探索让我转向了funcparserlib库。这次挑战让我深入了解了funcparserlib的强大功能。
词法分析(分词)
处理杂乱输入的第一步是词法分析(或标记化)。词法分析器(或分词器)扫描输入字符串,将其分解成独立的标记——进一步处理的基本单元。标记代表输入中有意义的单元,并按类型分类。本题中,我们关注以下标记类型:
运算符 (op): 例如mul、do、don’t。数字: 数值,例如2、3。逗号: ,,参数分隔符。括号: (和),定义函数调用结构。乱码: 与其他类型不匹配的字符或字符序列。
我摒弃了funcparserlib教程中常见的“魔术字符串”方法,转而采用更结构化的枚举定义:
from enum import Enum, autoclass TokenSpec(Enum): OP = auto() NUMBER = auto() COMMA = auto() LPAREN = auto() RPAREN = auto() GIBBERISH = auto()
登录后复制
使用TokenSpec.OP、TokenSpec.NUMBER等,提高了代码可读性、可维护性和类型安全性。
为了与funcparserlib集成,我创建了一个名为tokenspec_的装饰器,它包装了funcparserlib的tokenspec函数,简化了标记定义:
from funcparserlib.lexer import tokenspecdef tokenspec_(spec: TokenSpec, *args, **kwargs): return tokenspec(spec.name, *args, **kwargs)
登录后复制
利用tokenspec_,我们可以定义分词器:
from funcparserlib.lexer import make_tokenizerdef tokenize(input_str: str): tokenizer = make_tokenizer([ tokenspec_(TokenSpec.OP, r"mul(?=(d{1,3},d{1,3}))|do(?=())|don't(?=())"), tokenspec_(TokenSpec.NUMBER, r"d{1,3}"), tokenspec_(TokenSpec.LPAREN, r"("), tokenspec_(TokenSpec.RPAREN, r")"), tokenspec_(TokenSpec.COMMA, r","), tokenspec_(TokenSpec.GIBBERISH, r".") #匹配任何字符 ]) return tuple(token for token in tokenizer(input_str) if token.type != TokenSpec.GIBBERISH.name)
登录后复制
mul的正则表达式使用前瞻断言确保正确的语法。
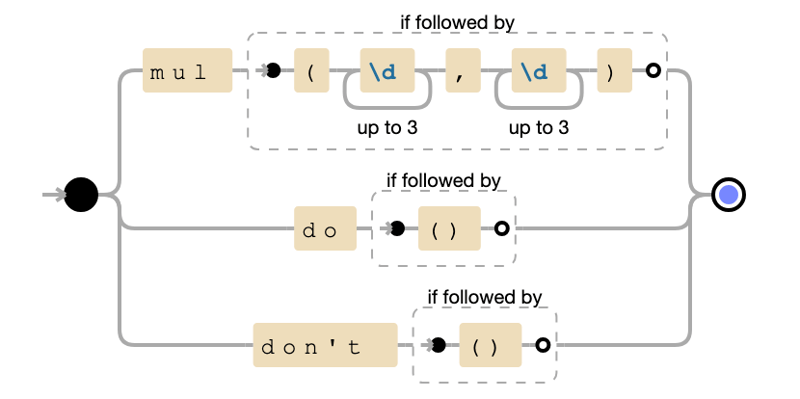
tokenize函数过滤掉乱码标记。
解析器实现
tokenize返回的标记序列将被送入解析器。为了简化解析器定义,我创建了tok_装饰器:
from funcparserlib.parser import tokdef tok_(spec: TokenSpec, *args, **kwargs): return tok(spec.name, *args, **kwargs)
登录后复制
数字解析器:
number = tok_(TokenSpec.NUMBER) >> int
登录后复制
解析规则:
from dataclasses import dataclassfrom abc import ABC, abstractmethodclass Expr(ABC): @abstractmethod def evaluate(self) -> int: pass@dataclassclass Mul(Expr): alpha: int beta: int def evaluate(self) -> int: return self.alpha * self.beta@dataclassclass Condition(Expr): can_proceed: bool def evaluate(self) -> int: return 0 #条件表达式不参与计算mul = (tok_(TokenSpec.OP, "mul") + tok_(TokenSpec.LPAREN) + number + tok_(TokenSpec.COMMA) + number + tok_(TokenSpec.RPAREN)) >> (lambda t: Mul(t[2], t[4]))do = (tok_(TokenSpec.OP, "do") + tok_(TokenSpec.LPAREN) + tok_(TokenSpec.RPAREN)) >> (lambda _: Condition(True))dont = (tok_(TokenSpec.OP, "don't") + tok_(TokenSpec.LPAREN) + tok_(TokenSpec.RPAREN)) >> (lambda _: Condition(False))expr = mul | do | dontfrom funcparserlib.parser import finished, manyimport operatorcall = many(tok_(TokenSpec.NUMBER) | tok_(TokenSpec.LPAREN) | tok_(TokenSpec.RPAREN) | tok_(TokenSpec.COMMA)) + expr + many(tok_(TokenSpec.NUMBER) | tok_(TokenSpec.LPAREN) | tok_(TokenSpec.RPAREN) | tok_(TokenSpec.COMMA)) >> operator.itemgetter(1)program = many(call) + finished >> (lambda t: tuple(t[0]))def parse(tokens): return program.parse(tokens)
登录后复制
难题求解
第一部分:
def part1(input_str: str) -> int: expressions = parse(tokenize(input_str.strip())) return sum(expr.evaluate() for expr in expressions if isinstance(expr, Mul))
登录后复制
第二部分:
def part2(input_str: str) -> int: expressions = parse(tokenize(input_str.strip())) can_proceed = True total = 0 for expr in expressions: if isinstance(expr, Condition): can_proceed = expr.can_proceed elif isinstance(expr, Mul): if can_proceed: total += expr.evaluate() return total
登录后复制
迭代改进
最初,我的方法涉及两次解析。现在,单次解析就完成了所有任务,提高了效率。
这次Advent of Code之旅让我巩固了词法分析和解析的知识。期待未来更复杂的挑战!
以上就是如何解析计算机代码,代码的出现 ay 3的详细内容,更多请关注【创想鸟】其它相关文章!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至253000106@qq.com举报,一经查实,本站将立刻删除。
发布者:PHP中文网,转转请注明出处:https://www.chuangxiangniao.com/p/2173733.html


